DERECHO PROJECT WEB SITE
Cornell University
Ken Birman (PI), Sagar Jha, Jonathan Behrens, Mae Milano, Weijia Song, Edward Tremel

DERECHO PROJECT WEB SITE Cornell University Ken Birman (PI), Sagar Jha, Jonathan Behrens, Mae Milano, Weijia Song, Edward Tremel |
|
News!
Beta release of the Derecho Collective Communication Primitives (DCCL). These are the workhorses of modern AI... and our DCCL outperforms other options!
Most current release: Find it at https://Github.com/Derecho-Project. These days you need a GitHub account with 2-factor authentication enabled to access GitHub URLs.
V1.0 release of Cascade, our platform for data and compute hosting in time-sensitive edge settings. Read about it here.
Goals and Approach
As seen in the image, a Derecho is a powerful straight-line storm capable of knocking down anything in its path. When remote DMA networking (RDMA) migrated from HPC settings into general purpose computing environments, our Cornell effort seized on the Derecho image as a motivating idea: we would view the network as an unstoppable, almost primal force, and find ways to redesign communication to get everything out of the way. You can read about our actual approach in references [8] and [1], but this concept shaped the whole project.
Our effort began in 2016, when Cornell was gifted a 100Gb RDMA networking switch and NICs by Mellanox (now a division within NVIDIA). Over time, we broadened the project to also support the dataplane developers kit (DPDK), which is a purely software stack aimed at supporting ultra-fast user-address space implementations of protocols like TCP, as well as standard TCP. The system was initially released in 2019, accompanied by a series of papers that we list at the bottom of this web page, and has been used by a number of efforts since then.
Derecho is a mature, well-tested system. It takes the form of a C++ library with bindings that make it easy to access from Python, Java, C# and other frameworks, like Microsoft's dotnet. We designed Derecho to be fully compatible with using other libraries and packages such as PyTorch, Tensor Flow, MXNet, Julia, etc. So the idea is really to create a universal set of ultra-fast communication options, almost like a communications kernel for modern networking. It works under Linux (our native choice) but also under the Windows subsystem for Linux, if you prefer that platform.
The Central Idea
To understand how we approached Derecho, it may be helpful to think about a standard 2-phase commit protocol. You find such protocols at the core of most distributed algorithms, including in the famous Paxos protocols used for state machine replication. 2PC is typically deployed in a crash-failure setting. A leader sends out some sort of request. Participants respond (perhaps including extra information), and the leader somehow combines this data into a commit decision plus, in many cases, ordering information derived from the participant replies. Then the participants commit the message. Sometimes there is an extra round tacked on, to facilitate failure recovery (for example, the participants might acknowledge that the protocol is preparing to commit, and only after the leader collects these acknowledgements does commit actually occur).
For example, here we see P sending m1... m4 to { P, Q, R }, using a 2PC pattern:
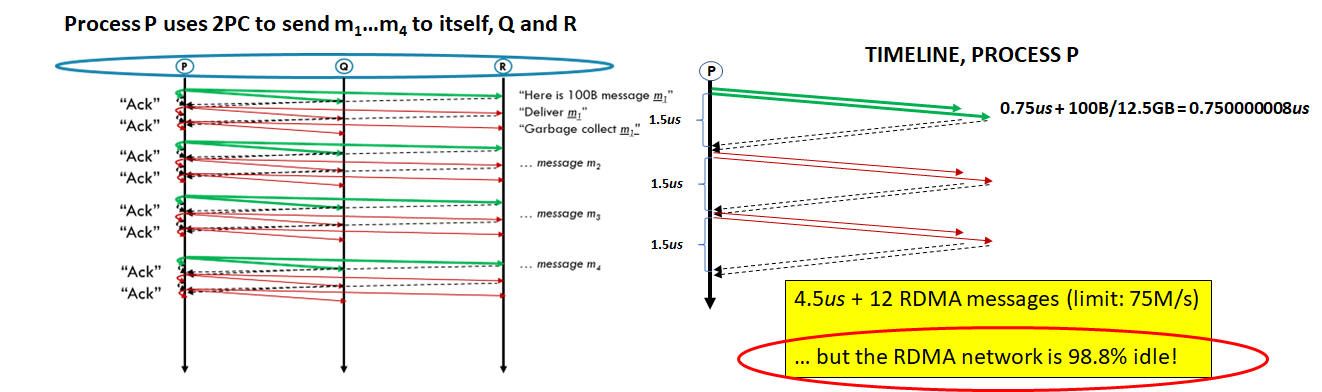
At RDMA speeds, it makes sense to ask how effective such a pattern will be -- especially in modern big-data settings, where we rarely do something just once. An AI system doing updates of a key-value store might be streaming millions of updates per second, not just one at a time. Well, if the 2PC pattern is used, data will probably be moved in stage one, but all of the other communication exchanges focus on "control data". Thus, we leverage the streaming speed of RDMA in the first step of the first phase. But after that, the limiting factor is suddenly going to be the RTT (round-trip delay) of the networking device.
RDMA often runs at 100Gbps (12.5GBps): as fast as the backplane inside a standard PC or laptop. These are per-link, one-way numbers: with two-way communication, the theoretical limit could be 200Gbps, although a memory bus in a standard computer might not be able to keep up with that speed. And if you imagine a set of machines that all have direct connections, every one of those links could be fully active, all at the same time! Some RDMA devices run at even higher speeds: 200Gbps is widely available, and in speciality settings it is possible to find 400 and Gbps devices and even faster ones. 1Tbps is apparently feasible, and the industry might not even stop there. The aggregate capacity is mind boggling!
Yet throughput isn't the only important metric. Optical-electronic conversion units impose delay associated with encoding and decoding bits, hence today's RDMA delays are already about as good as can be achieved. Well into the future, one-way RDMA delays will hover around 0.75us (this assumes a cluster or a cloud data-center; RDMA can't be used in WAN settings). RDMA round-trip delays are thus bounded by 1.5us. Such numbers may all seem blindingly fast, yet in fact RDMA data transfer is actually much faster than the round-trip speeds.
Knowing that we will probably have a stream of requests (a series of 2PC operations), we can easily come up with ways to improve on the basic pattern. We could initiate many requests concurrently, taking care to preserve sender order. One way to do this might be to have every member of the group participate as a sender, rather than having just one leader. With n participants we would hope for an n-fold speedup. We could have each participant run multiple threads (but here the thread contention effect could become an issue: in our experiments, locking delays and memory contention turns out to dominate any speedup with even 2 concurrent threads per participant). Batching might be a good option, and in fact is widely used in modern publish-subscribe systems like Kafka, as well as in dissemination systems (DDS). However, batching can cause a delay of its own (the time needed to fill a batch). The protocol will need to send partial batches if any request would wait unreasonably long. Yet even with all of these tricks used at the same time, a 2PC layered over 100Gbps RDMA would be unlikely to exceed 5% of the capacity of the RDMA link!
As an illustration, here is a timeline for an imaginary protocol using all of
those techniques. A thick green line is supposed to represent a batch of
messages (but because of timeouts, some batches are small, hence the green part
is thin).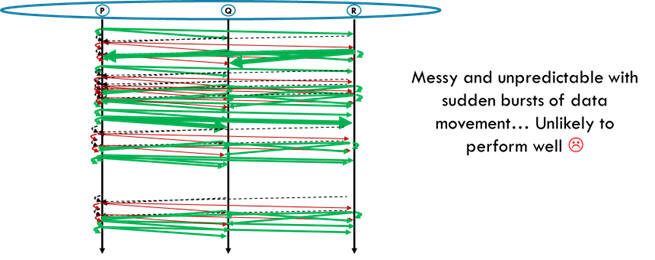 u
u
You can see an analysis of this in my slide deck (look at the Derecho section, starting around slide 32 of these slides, or read the same analysis in reference [8] or [1]). But if our goal is predictable high throughput and at the same time, low tail latency for individual operations, we'll be pretty unhappy with this run. Throughput isn't great and latency tends to be high even so. Moreover, lucky multicasts don't wait long, but on the whole, a long wait while a batch fills up is likely.
The magic that gets round-trip delays off the critical path turns out to be a decoupling of data movement (which we can think of as a TCP-style 1-to-n streaming option) from control data exchange (the equivalent of the acks and the negotiation around the commit decision). The idea is to run them both asynchronously: we'll send requests 1, 2, 3, .... on the data plane, pausing only if the system runs short on memory. This will stream data, so it should be feasible to peg the RDMA or DPDK network at near its performance limits. Then we can send control information related to each request separately, sneaking those messages in as a kind of second asynchronous channel. RDMA can easily do this:

In fact, Derecho goes deeper here. As we explored this idea we realized that there is a particularly efficient "monotonic" encoding of control data, that cuts the amount of control data dramatically. A whole series of additional ideas then suggested themselves: rather than batching on the sender side, which is slow as noted earlier, we could opportunistically look for batches of work to do on the receiver side of our protocols. This pays off nicely. In the references, you can read more about these ideas in [1] but also in [2] and [3]. In fact [3] is entirely focused on this one idea!
Monotonic data... and Monotonic deductive reasoning!
What would be a monotonic encoding of acknowledgement data? Suppose that an ack message contains the number of the acknowledged message: ACK 3, for example. A monotonic encoding would simply construe this to mean "I wish to ACK all messages, 1..3". The benefit is that we can just maintain a counter and, when it is time to send the next control data message (as you'll see above, these are sent regularly), the ACK field covers all messages received as of that instant.
A predicate for detecting stability might check to see if, for message k, an ACK has been received from all members of our little group. A monotonic predicate would find the largest k such that for all values less than or equal to k, stability holds for k. Combining these ideas, we send control messages at a high but regular rate, covering whichever messages have been received, and senders discover stability in batches, covering every message that can safely be construed as stable up to whenever they evaluate the predicate.
The central innovation of Derecho was to express every protocol using this idea. In some sense, it is remarkable that this proved to be possible! But we were successful... pseudocode for the protocol can be found in [1].
If the protocol looks different from a standard Paxos, can I trust it?
We proved our logic correct, by hand. The proofs appear in [1]. But then we went further and verified the proofs using Ivy, a checker similar to TLA+ or Dafny. With Ivy, you express your protocol as a set of actions operating on a distributed state represented in variables. Then you encode correctness as invariants. By translating the invariants to a Z3 formula, Ivy is able to either confirm that they always hold, or show a counterexample. Annie Liu's DistAlg group went on to do a new specification in the more powerful DistAlg domain-specific language, and a proof of their own. We are currently working on a fourth proof, this time with a Princeton-based researcher named Lennart Berringer who works in Coq (specifically, using a methodology called the Verified Software Toolkit) and a team at Stephens Institute of Technology headed by David Naumann, an expert in Coq theorem proving. Derecho is heading towards being the "most proved" Paxos protocol in existence! Read [8] for a more elaborated discussion of the merits of these different approaches.
Communication Primitives.
Enough design! Let's pivot and talk about what we built. Derecho offers quite a range of communication options. These include:
Collective Communications API
Many big-data systems use MapReduce, AllReduce, and some associated shard-oriented communication primitives, widely known as the CCL API (Wikipedia has a very nice treatment, here). Our version, DCCL, is at a beta readyness level as of December 2023 and should be ready for wide public use by February 2024.
This illustrates the AllReduce pattern. Processes 1, 2, 3 and 4 all have different data (for example vectors of floating point numbers). After AllReduce, all four have identical vectors, in which each element is "reduced" by combining the data from the four inputs (for example, by adding the numbers).
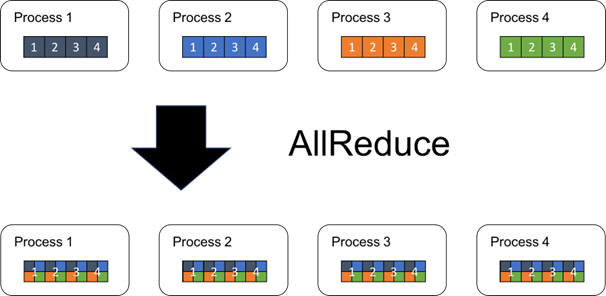
AllReduce could run on data in host memory, or data in GPU memory, or could take inputs from one source but leave the outputs in the other. The CCL library API is standard and covers these and other cases.
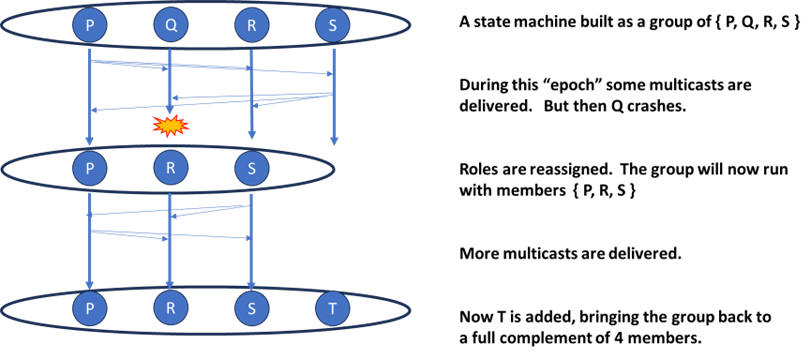
Virtual Synchrony Membership.
Derecho tracks the membership of a system using a model virtual synchrony. The idea is simple: there is a list of members internal to Derecho, automatically updated as members join, leave or crash. Changes are reported via upcalls to your application each time an update occurs (the data structure used in these are called membership views ).
Derecho automatically senses crash failures, but it won't handle hostile behavior (it is a crash-tolerant system, but not Byzantine fault-tolerant). We assume that normally, Derecho is used in a virtually private network or cloud, for example in a single data center, or compute cluster, or physically close nodes with WiFi networking. We trust the machines equally, and even trust them to detect failures (we use a low-level feature of RDMA for this, based on timeouts). None of these features is trustworthy if a system is successfully compromised, so you should adopt the view that if malware compromises one of your machines, nothing on that wide-area site can be trusted. However, we do provide an off-site backup option that can ensure recoverability of data up to the point when the compromise occurred (assuming you have some idea of how and when it occured). This is called WAN mirroring and is discussed below.
Accordingly, you should think of your system as follows. You first design an application, with the plan that it will run on some set of servers. You deploy your code to those servers (in any way you like, including with an application manager like Kubnetes or a cloud equivalent). Plan to have one application instance per physical host, or per virtualized container.
As your application instances launch, they automatically connect to the Derecho service using a configuration file that tells them which machines the service normally runs on. You'll edit this file, which also includes parameters such as the size limit mentioned earlier for small messages (and another limit on the maximum size of large messages). When the application connects, Derecho verifies that it is running on hardware with a compatible byte ordering, then Derecho updates the view and reports the new contents. The joining process has full access to its API once the first view has been reported.
We also support a second concept called an external client. This is an application that will not be part of the core of Derecho and is limited to sending P2P streamed and RPC requests. Thus, an application would often have some number of core servers, and then perhaps a much larger number of external clients. You should be able to use TCP or DPDK from external clients even if the core of Derecho is using RDMA.
Automated Layout and Sharding
Modern big-data systems often get very large. To help you structure your code, Derecho allows you to divide the members into what we call subgroups: the idea is that the main membership forms a top-level group, and you can specify any subset you like as a subgroup (overlap is allowed). These subgroups are additionally sharded. For example, K/V storage systems typically map keys to shards. Although you can fully control the subgroup and sharding patterm Derecho includes an autosharder that will additionally handle failure/restart sequences and elasticity, where the size of your application varies over time.
For example, a file system like Apache HDFS is automatically sharded. Each shard member holds identical replicas of the same data -- but each shard owns just a portion of the full data set. To see the full data set, a computation would need to run in a distributed manner, accessing all shards in parallel. The DCCL primitives would be a common choice for that step. In fact sharding dates to the earliest work on scalability at Google (and even before that, with examples such as MemCacheD: a distributed hash-map structure spread over a set of processes in a cloud). Google created MapReduce and AllReduce for shard-based computing. Apache then created the popular Apache framework, including its own open-source file system (HDFS), its own membership tracker (Zookeeper), and its own MapReduce implementation. These days that MapReduce version has become the basis of Spark/Databricks.
Thus Derecho is offering an Apache-like framework, but mapped to RDMA or DPDK for better performance. Here is a typical Derecho sharding scenario:
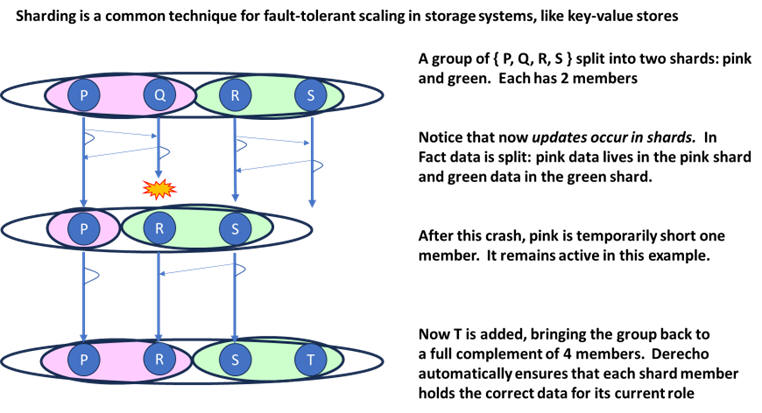
Notice that the Derecho multicast and atomic multicast and log replication functionality are deeply intergrated with the membership view. One-to-many operations are defined at a per-shard level: a reliable multicast is sent to a shard, and Derecho maps this to the membership per the most current view. In contrast, P2P communication works between arbitrary processes, and ignores the sharding structure. In the example above, an update to some object is first mapped to the proper shard, probably using a deterministic preagreed hashing function on the key. Suppose the object lives in the green shard. Next, the update must be given to some process in the green shard: perhaps, via an RPC request from an external client that is initiating the update request. That member turns around and does the atomic multicast (or state machine replication update) seen in the figure. And when it commits, the reply to the RPC can send back a success report to the external client. Derecho will automatically reissue such an update if needed.
We recommend that you think in object oriented terms. A subgroup is like a static class, and a shards is a bit like an object instantiated within such a class. Our APIs reflect this intuition. In particular, when you multicast to a group, we make this look like a generalization of RPC: you define a method to receive the incoming messages, and callers are automatically constrained to send exactly the data desired by the corresponding receivers (same types, etc).
For example, the sharded group in the figure could be a "file system" abstraction. Its API might be the standard POSIX API, perhaps via FUSE, a library we happen to support in Derecho. FIle system operations all map via FUSE to sharded key-value operations, put and get, and put in turn maps to atomic multicast. get simply does a local read at some process in the shard selected by hashing the request key. And how do file system pathnames become keys? In Derecho, we simply treat the entire pathname as a key! So a file name, or a key, are just synonyms!
How does data -- such as the data in a file, or the arguments to an RPC -- turn into "messages"? This is done by marshalling. The word is a synonym for serialization. Your data gets "serialized" into a series of byte vectors, one for each argument to the RPC call or each field in a data structure or object. The byte vectors are then turned into a list by the marshaller.
In Derecho we offer several forms of data marshalling. We called them "cooked" communication, meaning that we automatically will package the data you want to send into a byte vector for you. Use the "uncooked" modes if you prefer to do this step yourself. We avoided the word "raw" simply because we also provide a way to access reliable multicast independent of atomic multicast, and we call that a "raw" multicast API. So, we settled on "uncooked" for the case of an "unmarshalled" send where the sender's data is already in the format the receiver desires.
For the very fastest performance, you can often skip the serialization and marshalling entirely. Just construct your objects "in place" by asking Derecho for a memory slot. Put the data in a standard form that all your machines will recognize (for example, the Intel x86 data format). Now there isn't a need for any format conversions at all! An object such as this can simply be shared directly between a client and Derecho, and between a Derecho service on one machine and the service on another machine. All our high speed tests use this simple, powerful idea. But beware: if you mix AMD, ARM, Raspberry Pi and x86 servers, you'll need to pick a format and you may need to marshall on some of your machines because they don't use the same data formats in memory.
Not every failure can be overcome
In our example above, the pink shard still had one member (P), so all the pink data was continuous available. Yes, P is handling twice the load for a little while, and could become a bottleneck. But the data was still there.
What if P crashed too? Now our group would have no members of the pink shard at all! A put or get that maps to pink wouldn't have any member able to handle it! The pink data may still exist on disk, if the subgroup is configured for persistence (the data would all have been logged, with every member holding a complete log), but with all the members crashed, we would have to wait until one of the last to fail recovers (to make sure its log is complete) and then perhaps even make a replica for safety. We decided to automate all of these steps, resulting in the algorithm described in [4].
There are some systems that can deal with problems like this. For example, in Amazon's famous DynamoDB approach, if the pink shard isn't available, the client trying to do the pink operation would just ask the green shard for help. Inconsistency can result from this. DynamoDB might have temporary amnesia and lose some updates, but then find them again later.
Derecho allows you to specify the desired behavior, but the normal approach we take centers on the idea that a configuration with no pink shard members at all is "inadequate for safe operations." In that situation Derecho just waits until a process restarts and joins, enabling the pink shard to be automatically restored (repaired if needed) and for normal operations to resume. No inconsistency is ever visible, but there might be a brief period with no availability if two processes of the same color happen to crash at the same time. The number two has no magic meaning here: you can specify shards of any size you like.
What made it hard?
Derecho was quite a challenge to build! Modern programming styles tend to favor use of large numbers of threads, lots of locking, and copying is hard to avoid. But at RDMA speeds, copying is often much slower than RDMA transfers, so a single copying event can dominate the entire critical path. Threads are widely perceived as a way to speed computations up, but we found that Derecho's main loop actually ran faster with just a single thread because this let us eliminate memory contention and lock contention that would arise with even two threads. On the other hand, the user's code obviously needs to run in threads distinct from the main loop, so we needed to design a smart way to interface our logic to the user's logic.
Some of the challenges involved interfacing to RDMA or DPDK so as to move data (often via multicast) at the highest possible speeds. For example, in Derecho's RDMC layer, the pipelined multicast we developed achieves incredibly high bandwidth by creating a virtual overlay network on the members that want replicas, in the shape of a virtual hypercube. Then we implement a tricky scheduling pattern first proposed by a group of combinatorial mathematicians at Stanford (but never previously implemented), resulting in a very deterministic data exchange that nonetheless feels reminiscent of BitTorrent. But on top of all this we also had to worry about members experiencing brief delays, and how to make the protocol tolerant of network scheduling "jitter". RDMC is a pretty amazing data transport protocol! Read about it in [2].
Yet it turned out that not every message is big enough for the RDMC approach to pay off. So Sagar Jha, who invented Derecho's core framework, created a second protocol called the SMC, for small messages. More recently, Weijia Song added an out of band zero-copy capability for medium sized messages. All of these are really important for high performance, but each arises in a different setting. Derecho picks automatically, and your application simply benefits. But you would need years to build something equally sophisticated, which we can say with some confidence because it took us years to do so. Convincing skeptics that the solution is correct can be a puzzle, too! We ended up using formal proofs, and verifying them with formal checker tools. Even that step took many months of effort (and in fact got us hooked on verification, so the work continues even no, although we are looking at questions far beyond the ones arising in Derecho per-se).
But the hardest and most exciting challenges centered on sharing control state through Derecho's SST, which is implemented as a lock-free shared memory data structure: a table, in which every top-level group member "owns" a row (and can write to its own row) but sees copies (read-only) of the rows owned by its peers. The SST is an ideal data structure for RDMA and DPDK, because our monotonic approach to control data representation only requires sequential memory consistency. But this did mean that we had to "refactor" (redesign) a virtual synchrony membership protocol, atomic multicast, and durable Paxos-style log replication in a way that maps cleanly to the new representation. Doing so turned out to be less difficult than expected in part because of a very old story that isn't often told.
Back in the 1980's, Yoram Moses and Joe Halpern published a seminal series of papers on "knowledge and common knowledge" in distributed systems. This evolved into a distributed temporal (epistemic) logic for reasoning in distributed systems, where process P might know something, Q might learn of that from P, R might deduce that every process knows this fact, etc.
Yoram spent quite a bit of time with the Derecho team in 2017 and from this, we were able to recast our new protocols in terms that could be explained using that temporal logic of knowledge [8]. This was exciting, but more to the point also enormously valuable. It helped us simplify the needed proofs to demonstrate that our protocols really are equivalent to more classic ones.
Of course, we made some decisions that depart from classic Paxos. Paxos generally is defined "first", with dynamic membership adaptation added later. We went the opposite way, tracking membership and defining our protocols during stable epochs. The big advantage to doing so is that during an epoch, every process knows the membership (a bit like common knowledge! This comparison is elaborated in [8]). To take the idea even further, we settled on a fixed atomic multicast ordering rule (round-robin among active senders), although Derecho does send null messages, automatically, if a process is next to send and has no messages ready. Then we had to arrange that the multicasting loop didn't become an infinite high-rate series of nulls. But once we had all of this working, it worked like a charm, gave the high performance that probably appeals to you, and with the help of Yoram's knowledge logics, we were able to prove the algorithms correct and even optimal. One way that Derecho reduces the odds of this sort of failure centers on the idea that if the processes in a shard are selected to not share the same machine, power supply, network router, A/C unit, etc, then most likely the crash of one won't be correlated with the health of the other. You can read about the technique we use in [5].
Summary of Innovations
Bottom line? Derecho works, incredibly well. There is no faster system to be found, and arguably it will be very hard for anyone to "beat" us because for many purposes, Derecho pretty much pegs what the network is capable of supporting.
Derecho being optimal: Does this matter?
Surprisingly, even though we created the system, we view this more like a curiosity than a core thing. We are hoping you'll use Derecho because it is the fastest technology out there, and our speed translates to faster model convergence as you train your AIs, faster replication of new VM images and critical data sets, and other basic, practical benefits.
But in fact we are proud of the optimality of the system. There was a period when researchers created dozens of Paxos variants. It is kind of amazing to have the very first that can make this claim.
Optimality comes in many flavors. As it turns out, we seem to be optimal in all of them!
Here's the bottom line for optimality: As an engineered artifact, an asymptotic theoretical property sometimes isn't really all that important. But progress for Paxos or Derecho isn't really an asymptotic question, and the particular optimality theory we cite in [1] and [8] is quite pragmatic in its goals. Derecho is really running at the peak speed this class of hardware can achieve.
But some systems will end up outperforming us, even so. Joe Izraelevitz has a system called Acuerdo, built over the same lower layer we use in Derecho. In his experiments Acuerdo outperforms Derecho during situations in which large numbers of processes stall, but then restart (this could also be mimicked by noisy communication links, which might time out but then recover). Acuerdo is not as complete a platform, but that style of protocol might be a better choice in a system built with wireless links, for example.
Systems that use hardware features we haven't explored could beat Derecho, too. For example, our protocols only send a given byte over any particular RDMA/DPDK link once. But if multiple RDMA or DPDK links share the same physical link, this might not guarantee optimal use of the hardware. Even RDMC, our big-object multicast, could be improved with data-center topology: it would make sense to use some other protocol at the top-of-rack level but then use the binomial pipeline inside a rack. And there are systems that provide RDMC-like functionality within the data-center fabric itself. For host-to-host communication, Derecho does the most useful work with the fewest network transfers, but with that sort of magic hardware, perhaps other options could be feasible.
Still, you won't find a standard host-to-host library that can outperform Derecho. Sending fewer messages would (provably) result in inconsistencies such as out of order delivery or packet loss. We already send as fast as the network can absorb the requests, and our experiments show that the network is 100% busy. None of those packets are wasted work. This protocol is pretty much as good as it gets!
Download Site
Our development site is https://GitHub.com/Derecho-Project.
Best of Breed Alternatives
Many people considering Derecho are also thinking about alternatives. In fact, we recommend that you also consider RaFT and Zookeeper. Generally, we view Derecho as a winner compared to all alternatives, but in fact there are situations in which one of those may be a better choice.
RaFT is a library for a Paxos-like protocol, but not optimized for ultra-fast networking hardware. The technology is easy to use and widely popular, and if your level of load will be small, it can be a great choice.
Zookeeper is a kind of file-system within the Apache software stack for cloud computing. It creates files that hold membership views, and file updates are implemented using a protocol that offers some of the Paxos replicated update features (but not all of them). Most Apache cloud solutions use Zookeeper. It is extremely easy to set up and work with, but quite limited in terms of speed and file size. In fact we have been approached about perhaps rebuilding Zookeeper around Derecho, but up to now have not tackled that task. Our Cascade project takes a somewhat different direction.
Derecho is the best choice if your application does a lot of communication and needs the fastest possible performance for all communication actions. However, it isn't trivial to learn to use, and isn't a drop-in replacement for RaFT or Zookeeper.
The Derecho DCCL primitives are an outstanding choice if you are building an application that will run for long periods of time doing great numbers of AllReduce or MapReduce operations.
Key Participants
The lead developer on Derecho was Sagar Jha, although Weijia Song and Edward Tremel and Mae Milano all contributed to many parts of the system, and many undergraduates and MEng students played smaller roles. Ken Birman led the effort.
Further Reading
| [1] | Derecho: Fast State Machine Replication for Cloud Services. Sagar Jha, Jonathan Behrens, Theo Gkountouvas, Matthew Milano, Weijia Song, Edward Tremel, Robbert Van Renesse, Sydney Zink, and Kenneth P. Birman. 2019.ACM Trans. Comput. Syst. 36, 2, Article 4 (April 2019), 49 pages. DOI: ttps://doi.org/10.1145/3302258 |
| [2] | RDMC: A Reliable Multicast for Large Objects. Jonathan Behrens, Sagar Jha, Ken Birman, Edward Tremel. IEEE DSN ’18, Luxembourg, June 2018. |
| [3] | Spindle: Techniques for Optimizing Atomic Multicast on RDMA. Sagar Jha, Lorenzo Rosa, and Ken Birman. In 2022 IEEE 42st International Conference on Distributed Computing Systems (ICDCS), 2022. Previously available as: arXiv:2110.00886 (October 2021). |
| [4] | Stabilizer: Geo-Replication with User-defined Consistency Pengze Li , Lichen Pan , Xinzhe Yang , Weijia Song , Zhen Xiao , Ken Birman. IEEE ICDCS 2022 in Bologna, Italy July 10th – July 13th, 2022. |
| [5] | Reliable, Efficient Recovery for Complex Services with Replicated Subsystems. Edward Tremel, Sagar Jha, Weijia Song, David Chu, Ken Birman. IEEE DSN ’20, Seville, Spain 2020. |
| [6] | DerechoDDS: Strongly Consistent Data Distribution for Mission-Critical Applications Lorenzo Rosa, Weijia Song, Luca Foschini, Antonio Corradi, Ken Birman. COM 2019 - 2019 IEEE Military Communications Conference (MILCOM), November, 2021. |
| [7] | RDMA-Accelerated State Machine for Cloud Services (PhD dissertation). Sagar Jha. Cornell University. December 2022. |
| [8] | Monotonicity and Opportunistically- Batched Actions in Derecho. Ken Birman, Sagar Jha, Mae Milano, Lorenzo Rosa, Weijia Song, Edward Tremel. 25th International Symposium on Stabilization, Safety, and Security of Distributed Systems in Jersy City, New Jersey, October 2-4, 2023. |
| [9] | Guide to Reliable Distributed Systems. Building High-Assurance Applications and Cloud-Hosted Services. ( Texts in Computer Science). Kenneth P. Birman. Springer. 2012. |