| Cascade
Project Contacts: PI Ken Birman Project Director Weijia Song Team leaders: Thiago Garrett, Lorenzo Rosa, Edward Tremel, Alicia Wang |
 |
News
-
Release 1.0 of Cascade will be in January
(after the holiday break). A near-final Beta is available now on
https://GitHub.com/Derecho-Project/cascade
-
End-to-end zero copy scheme is up and running
in an alpha status; it will soon support user-developed AI logic (UDLs)
hosted in docker containers using the same API as for UDLs in the
Cascade address space.
-
New object grouping mechanism ("afinity"
grouping) and scheduler (Compass [4]) showing big speedups!
Goals
Cascade is about AI performance. Many AI researchers are focused on making the AI logic itself faster through foundational advances in the MLs themselves. Our angle is to focus on the computer (which could be a cloud server, or could be a dedicated machine in a rack) where the AI will later be deployed, particularly for inference and classification tasks. We want to minimize the wasted effort when this set of servers runs your jobs.
Wasted computing and store resources receives surprisingly little attention, yet turns out to be a large effect. By studying the way that existing AI applications are typically hosted on standard platforms and standard operating systems, we easily identified a number of inefficiencies. Added together, we realized that many ML systems are running at a tiny fraction of what should be feasible: overhead factors of 3, 10, even 20+ are not unusual! For example, a program that should be able to run using 10% each on five machines might actually be using 85% each. These inflated overheads translate to hugely inflated costs of ownership for the companies that depend on today's ML systems. Moreover, it causes their ML to slow down: applications like interactive ChatBot systems are much slower than they should be (even granting that some of the AI tasks are slow to perform).
In our work on Cascade, we tackled these performance-limiting barriers one by one, and achieved dramatic speedups. Yet for the user, this is often transparent: in many cases no user-visible code changes are required at all. In fact later on this page we quote some comparisons between applications on Cascade and on standard clouds (like AWS or Azure), showing remarkable speedups. It turns out that we didn't change the AI codes at all -- we ran the same code on Cascade and on the standard clouds. Yet we obtained huge speedups.
Some speedups came easily, but others forced us to innovate: Cascade is mostly lock free, offers zero-copy data paths from data source to the compute location, has surprisingly powerful consistency guarantees, and can safely be used to host sensitive edge data in applications where ensuring privacy and security might be important.
Cascade isn't just for running existing AI faster. It also enables a new generation of "temporally aware" applications. In fact, time is a central theme throughout Cascade.
The system has highly optimized time-indexing features to make it easy to fetch data over a period of time as part of a trend analysis. Clocks are highly synchronized within the system, and we've gone to great lengths to minimize tail latencies and also to avoid late outliers for all functionality users can access. Even when an AI treates Cascade purely as a data store and ignores these sophisticated temporal features, Cascade has such predictable performance that it can be treated as an O(1) MemCacheD service. Yet our APIs mimic the same low-level K/V interfaces offered by systems like DynamoDB and CosmosDB. Moreover, when data is updated concurrently by multiple sources, Cascade's built-in version control layer can be used for a "compare and swap" behavior: lock-free atomicity, at least at the level of individual K/V tuples (we do not support full transactions across arbitrary data).
Our approach is particularly effective if your main prioritity is to avoid end-to-end response delays in inference or classification tasks, but Cascade also achieves higher throughput: It can do the same job using less hardware, and with less electric power consumed. Jump to the end of this page for some numbers to back up these claims, and links to papers with full details.
Our back story
We created the Cascade system as a follow-on to the Derecho system, where we set out to build a modern communication library able to leverage network acceperators and obtained really amazing performance for a wide range of communication tasks, including durable data replication.
But then we encountered a puzzle. In the past, it was common for systems programmers to build applications directly from scratch. That approach is less common today. We began to think about how the benefits of Derecho could be made accessible to people solving today's important problems. Those puzzles mostly tied to AI, and that led us to start dialogs with a tremendous range of teams trying to use AI in demanding settings.
What we discovered is that while AI developers love the cloud for big-data tasks like inventing new image or text analysis tools, and for training their AIs, some of the people who are being asked to deploy those AIs are encountering barriers -- systems barriers, of just the kind our Cornell group is good at solving. As an example, consider an application that captures new images from a camera. It would need to either run the computer vision classifier model directly, or upload data to the cloud first, so that the script for running the vision classifier can find the photos in the cloud "binary large objects" (BLOB) store. The biggest performance bottleneck will probably be the internet connection from the camera (or the computer hosting it) to the cloud! So much time can be lost just doing the upload that there would be no point in even talking about real-time or time-sensitive computing.
We quickly discovered that a lot of people are facing exactly this issue. For example, when a computing system inspects products in a factory setting, it is important to detect problems quickly so that they can be corrected at the inspection station, before the faulty component moves to some other part of the factory. Here you might have cameras to photograph the components, AI vision systems to decide if they are defective, and then some form of automated system to shunt defective parts into a bin for repair (or recycling).
Cornell has a big effort to explore automation in agriculture, where you might have drones flying over fields to check for insect infestations, robotic tractors and sprayers, automated milking parlors for cows, automated cleaning system to wash debris into tanks where nutrients can often be extracted, etc. People exploring smart power grids, smart cities and smart homes all showed us scenarios that are important in their domains, and hard to tackle today.
There is a big push into augmented reality underway. Here are
several concepts shared with us by researchers at Microsoft. Both
clearly require ultra-fast AI on image streams.
On the left we see a technician servicing a turbine, using AR googles in an
application assisted by an AI that fuses data collected from sensors such as
air quality monitoring units, vibration detectors, etc. The AI can
then offer guidance driven by schematics and various hypothesis about where
the problem might be arising. This sort of partnership of human and AI
will need very rapid AI responses.

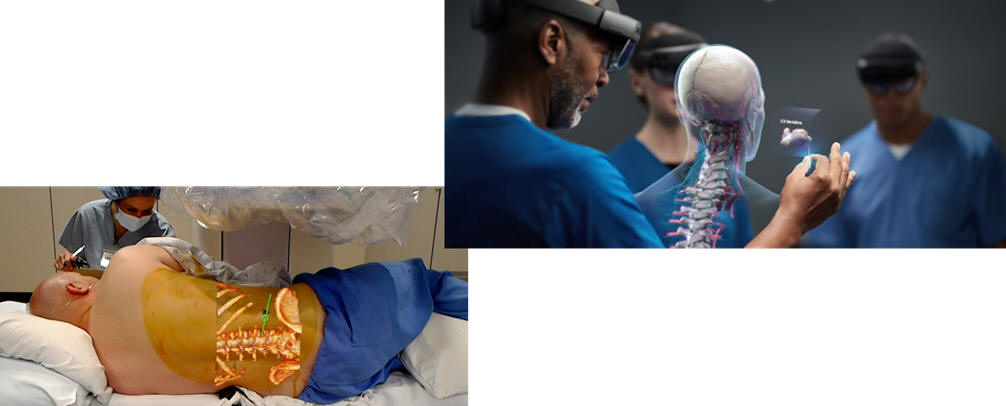
On the right, we see a surgeon trying to understand precisely where a nerve becomes pinched by asking the patient to move their arm while visualizing the cervical spine using data from an MRI imaging unit. Below we see the same technology used to assist in a surgical procedure that was planned offline but now needs slight fine-tuning based on the patient's actual position.
The ability to do AI quickly requires very fast AIs, so the game is over if the AI itself needs seconds to formulate a response. But computer vision AIs tend to be very fast compared to conversational ChatBots. For example, later in this document we'll discuss an AI that can monitor a traffic intersection like this one, sensing potential accidents and warning everyone (probably using flashing red lights on the poles) within 350ms of a risk being detected! The AI we use for that has multiple stages and even so, is able to respond in far less than one second.

Even a ChatBot could find a real-time responsive database useful. Consider ChatGPT. GPT4 was trained on data collected up through early 2021 (asking it what was the most powerful recent hurricane will make this clear). To "contextualize" chatting with it today, it will need to know about current events relevant to the coversation. If you were building this application right now, it would be common to try and build up an elaborate prompt (input to the chatbot) containing all the extra information needed. But over time, those current data prompts would become very complicated.
The obvious step is to view the context of a query as a kind of very easily-accessed, ultra-fast database (similar to Berkeley's MemGPT). The context data does need to be held in memory for adequate speed: granted, a chatbot isn't a real-time system, but it will still want very predictable and fast responses from its database. In fact, and this is something any PyTorch user would confirm, the ability to do database queries is built right into PyTorch. The same is true for Spark/Databricks (they call them RDDs), Tensor Flow, MXNET, and any Microsoft Azure platform that supports LINQ. So... these chatbots don't want full SQL database support because they plan to do the querying on their own -- all they need is the data, in a rapidly accessible form. We believe that the answer to this would be an ultra-fast simple key-value store, just like the ones used throughout Google, Amazon and Microsoft.
All of this leads to the opportunity on which we focus in the Cascade project. We envisioned it as a single system covering all of these cases. More specifically, Cascade
- Hosts data in a set of servers, using a sharded key-value representation that can scale without limit. It also has powerful correctness (consistency) properties, coming from the use of Derecho to update replicated data.
- Makes it easy to look data up by time, or to fetch a series of data items over a period of time (like: "positions of this taxi cab at 100ms spacing for the past 10s"). This is helpful when an AI watched something that happens over time, such as determining where those taxis seem to be going (and whether the bicyclist might force the taxi to swerve, and whether a pedestrian could then be in its path!)
- Offers flexible standard ways to access this K/V data. This may be a surprise to some readers, but it is well known that file systems can use a POSIX (Linux) API, totally standard, and yet store their data as K/V data. Apache's Hadoop HDFS does this, and so does the famous Ceph file system. Amazon S3 is built this way, and Microsoft Azure's storage fabric. We have a POSIX API for Cascade too! It isn't quite as fast as just using the K/V API, but if your exiting program expects to read and write files, you can just run it on Cascade with this file system API linked in, and it will work transparently. Moreover, we also support a message oriented middleware layer almost identical to Kafka's API, including both a store-and-forward (pub/sub) case and a data distribution bus (DDS) case. All of these map to the same K/V infrastructure, automatically.
But we need to do more because AIs depend on enormous data objects. Again, this could be a surprise if you've never actually worked with them. But a typical AI comes in three parts (or more!). One part is the software itself, which might be coded in PyTorch and using a GPU to speed things up, or might be coded for direct host computing. If you peek inside, you would probably see formulas (linear algebra, with data held in vectors, matrices, or higher dimensional tensors), and a great deal of matrix arithmetic. In fact GPUs are used mostly just for that specific task, a bit like a calculator into which you can load data, then perform a series of operations, and then read the results out.
Next we have what is called a hyperparameter object. This is a kind of configuration file for the AI. A transformer or CNN or random forest needs to specify a wiring diagram, what primitive components the random forest uses, and how all of this is wired together. If the AI does image analysis, it may need to know the photo format and dimensions. All of this data normally would be encoded into a configuration file, which is what AI developers mean by hyperparameter object. It could be a few hundred lines long, and you might need some special training on the particular AI to come up with the proper values. In fact hyperparameter search is an entire research area, and is a first step in training a general purpose AI: the task is to find values that work well for a particular domain.
Beyond this is the AI parameter vector itself. Training involves computing a vector of weights that are assigned to the wiring diagram internal to the AI. This is a slow, iterative procedure that normally occurs offline and we don't anticipate that Cascade would be widely used for this purpose: there are speciality systems today that are highly optimized exactly for training. It can take hours, days... even months. But the output of the process is a vector of numbers that correspond to the weights. When we say that a node in the graph shown earlier is an AI model, we really mean "consisting of its code, its hyperparameter object, and its previously trained parameter vector." Thus there would normally be three kinds of objects, and while some of them might live in the normal file system (like the code), the others would typically be stored directly into Cascade.
Some AIs will have additional objects on which they depend. These could include the context-setting database mentioned above, or a reference image that a new image will be compared with, or a collection of previous locations of a taxi cab that this new image will be used to extend so that the trajectory of the taxi can be updated.
Thus, a typical AI node might represent a computation that actually will run on multiple servers, to benefit from parallelism. And it might consist of multiple objects -- multiple keys (or file system pathnames, because in Cascade a key looks just like a file pathname), all of which are needed to actually perform the task. The node would have inputs (incoming edges in the directed AI graph) such as photos, or video snippets, or audio utterances, and when all of these are available, the AI task can run.
But it gets even more tricky. Most time-sensitive AI applications will consist of a directed graph of AIs. Today many AIs are still built as a single monolithic system: you design the AI for some task, train it, then deploy the trained model into a target environment where it will be used for classification or inference. But as AIs have gotten larger and larger, this simple way of thinking about AI has begun to evolve. First, the AIs themselves are often designed as distributed programs, frequently using the collective communication library (CCL) primitives: AllReduce, MapReduce, etc. But next, to reduce the size of the AI models themselves, the AI might be broken into a collection of smaller AIs: what people call a mixture of experts or a mixture of models approach. For example, ChatGPT4 would have a model size of about a terrabyte, but by breaking it into a collection of separate AIs, OpenAI managed to reduce the model sizes to a multi-gigabyte size that today's distributed computing systems can manage.`There is also a growing desire to just reuse existing AIs as a step to simplify creating new ones. The thinking here is that because training an AI can cost millions of dollars and use immense amounts of computing resources, we should train "general" models and then specialize them for particular scenarios using less costly steps: few-shot retraining, prompt engineering, contextual databases, etc.
Thus, the typical AI in a modern "edge" setting (a factory, or farm, or
hospital, or any other setting where taking actions quickly is part of the
requirements) will often be built as a cooperative set of AIs that are
individually distributed programs, and that communicate with one-another
using a pub-sub message bus like Kafka, or by sharing files in a storage
system like Apache's HDFS, or using a key-value model like Azure's CosmosDB.
Here is an example shared by Microsoft's FarmBeats team. The idea is
to try and use predicted weather data to anticipate that fields might flood
and take preventative action, like moving a herd of cows or harvesting a
crop before it becomes soggy.
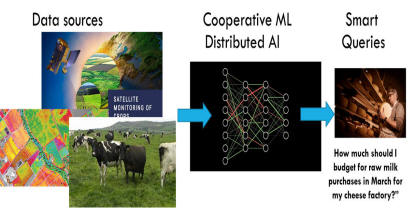
Notice the graph representing the potentially complex sequence of AIs cooperating on the task. We might have one AI (one node) deciding what satellite imaging is needed. Another could be predicting weather. Yet another, different, AI could be using that data to anticipate flooding risks. By the time the end user (in this example, a dairy owner who makes cheese) gets answers to his queries, dozens of independent AIs may have participated. Moreover, data is being shunted from AI to AI: the edges in the graph. This could include segmented images, identified objects, schematics for the factory, biomedical data for the surgeon.
In our work on Cascade we've become convinced that all the examples given above are best solved in this same way: using a data flow graph in which the nodes are entire AIs. But those AIs might themselves be distributed systems, perhaps built using AllReduce or MapReduce: that a single node in the cooperation graph could actually be a DNN running on multiple machines:
Thus, our little data flow graph showed 24 nodes, yet these could themselves be running on multiple machines each! The single job might require hundreds of machines, per event that triggers activity. Of course, the whole idea of a cloud is to support multiple tenants who securely share hardware. So these same machines could also be handling other tasks, all at the same time. Application owners would pay for resources consumed, in a cloud "function computing" model (sometimes called a lambda model, or a stored-procedure model). While my application is idle, your application might be running, and this amortizes costs: rather than pay for an entire cluster of 200 computers just for my use case, a large set of applications all share that cluster, and on a per-use case, costs are driven quite low!
Many systems move the data to where the job will execute.
But in the edge, the data is too big to move quickly.
In Cascade, we send the jobs to the data they depend upon!
An issue now arises. We have this vast number of computational tasks to run -- to "schedule" -- onto our pool of hardware (probably a cluster of computers shared by a scalable collection of jobs, possibly owned by different users). The jobs can be understood as data flow graphs, and may even look fairly simple at first glance, but once we "expand" the graph to show how many machines are needed for each of the parallel compute stages, could be quite complicated. And in this fully expanded representation, each individual node may actually depend on a collection of objects... some of which could be massive. Moving them at the last moment will wipe out any real-time or even quick response capability.
What we decided to do in Cascade was to start by grouping associated objects, so that if some set of five objects tend to all be needed concurrently, Cascade itself can put them at the same place (on the same shard). Now we have a small set of identical replicas, all of which are prepared to run the corresponding compute task. They have the code, and the dependent data (the hyperparameters, the model parameters, etc). All they lack is the input. Thiago Garrett built this feature. We call it an affinity grouping mechanism.
Shard sizes are totally flexible. Some shard could have 2 members (the minimum for fault-tolerance), yet in some other setting that puts that subgroup under more load, could equally well have 10 members per shard. As the AI developer, you get to decide this.
So, consider some compute task. Perhaps it wants to run some operation on a photo. For speed, we will run this as a parallel task with one compute step per shard in a sharded store containing data used for the vision task.
Concept: Scalable consistency
Imagine an urban safety system for intersections that sometimes sees ghosts: a taxi drives past but later, the camera suddenly shows an old image of that taxi. Or one that sometimes generates mashup images, showing a taxi in the intersection, but sort of mixing that photo with one of an old lady crossing at that exact spot. The individual images would be valid ones, yet by showing them out of order or mixing the two ages of images into one retrieval, we end up with a nonsense image that could confuse any image analysis we might want to try.
You will probably recognize this as a form of database consistency: the famous ACID properties (also called transactional atomicity with serializability). Seemingly, a smart traffic intersection would want a guarantee like this from the storage system. Should Cascade be designed as a database?
A famous paper by Jim Gray, Patrick Helland and Dennis Shasha made the case against trying to provide database-style serializability in scalable systems (the called it "The Dangers of Database Replication, and a Solution" and published it in 1996). The argument centered on a paper-and-pencil analysis: with a database that fully replicates the data it holds and then handles a mix of totally general transactions, then even with almost entirely read-only queries the rate of locking conflicts and abort/rollback/redo events would rise rapidly both in the number of transactions sent to a scalable system, and in the number of servers on which it runs. In fact the rate of growth predicted by the paper was shocking: with n servers trying to handle t transactions against a full replicated database, they anticipated an overhead growing as roughly n3t5 meaning that if we take some deployment and double the number of servers, then double the load on them, rather than keeping up with demand, the system would actually slow down by a factor of 256!
This is actually why nobody builds massive databases today. Instead, we shard: we take our database or K/V store and break it into s chunks (the shards), each with distinct subsets of the data. Applications are expected to send one request at a time (not an atomic transaction that might do a large number of reads and writes), and each request runs on just a single shard. A system using a mechanism like the one mentioned above could go a tiny bit further: Such a system could update a set of related objects that are grouped onto the same shard. But this is about as far as it goes.
Yet we don't need to toss out all forms of database-style consistency. Cascade uses an atomic multicast or a persistent state machine replicated update for update operations: the former if the data is entirely hosted in memory, and the latter if the data is also logged. These totally ordered updates certainly can scale: each shard is treated as a totally independent entity. Want more capacity? Configure the system to have more shards. In effect, an atomic multicast is like a mini-transaction, updating just one K/V object (or just some small set that were associated together and can be thought of as one composite object).
We can actually take this a little bit further with no loss of performance. Think about a get issued by some process P shortly after a series of put operations by Q, R and S. Perhaps, Q and R and S are tracking vehicles in a traffic intersection and P is checking for collision risks. What properties would matter?
Clearly we want updates to preserve the order in which they were issued. Otherwise, if Q is actually updating the location of some taxi T, T might seem to jump around: it could zoom forward due to a missed update, but then seem to jump back when the update turns out late and out of order. But this isn't hard to enforce provided that we number our updates, just like air traffic controllers number flight plan changes. Cascade supports this form of versioning and never allows the identical version number to be reused (a version of an object cannot be written, but then overwritten with different data).
We can also avoid gaps in the stored history. If our taxi was seen at locations t1, t2, t3, and the application asks for the recent sightings, we shouldn't omit t2 while returning t1 and t3. Cascade has this gap freedom guarantee (also called a causal ordering property). Any application that reads t3 would also see t2 and t1 if it tried to access those versions by version number or by time ("give me the locations of this vehicle over the past 10 seconds").
And finally there is a question of stability. In Derecho, a piece of data is stable if it is final and all prior versions are final, too. A very new update is initially unstable, but becomes stable after a few tens of microseconds. Additionally, we want to be sure that no data from an earlier time is still propagating through the system. For example, if we just witnessed our taxi at time now, it would feel like a causal gap for the system to not know about a sighting of the same taxi that was recorded at time now-10us. But it does take time for updates to be stored, and there could be a brief window of temporal instability. Cascade handles this with a kind of barrier. It transparently delays temporal data retrievals that try to access a time window that hasn't become stable yet. Again, this is a matter of a few tens of microseconds.
Stable data never changes: it is totally immutable. So once data does become stable, queries against it are totally reproducible and give a determined, final result.
Databases actually have a term for this mix of properties: linearizable snapshot isolation. It means "the past is finalized, and won't change." Nothing more than that. In this model, a query won't need any additional locking. Cascade is able to separate the data update path from the data query path, and both are lock-free!
Thus Cascade is able to offer a very powerful consistency property, for free (well, there are some tiny delays as mentioned above -- typically measured in tens of microseconds). And yet with this basic, inexpensive model we can eliminate all sorts of situations that might otherwise be deeply confusing to an AI!
Concept: Cohosted data and computation
Are we there yet? By now we have a lot of
powerful machinery at our fingertips. We can design applications
to capture images, relay them to servers, and then run an AI inference or
classifier to understand the image content. Today this kind of
solution would typically be
-
- Uploading images or videos (or radar, lidar, soil moisture maps...)
can be incredibly slow.
- The BLOB store itself will want to replicate your image (in fact, it is just a K/V store with its own sharding pattern!) And it probably doesn't use Derecho RDMA for that step. More time will elapse.
- Triggering a function often entails making a new container and loading code into it, starting the PyTorch runtime, and binding to any dynamic libraries the user is working with. A properly configured GPU might also be needed (one with the CUDA kernels corresponding to the operations used by the particular AI computation). Some AIs even use FPGAs that might need their own FPGA kernels downloaded into them. Unless we do this step often enough so that a "prewarmed" machine is handy, more time will be lost!
- Now the AI task can finally run. But as its very first step, it will probably have to download the dependent AI objects mentioned above, unless it finds them in cache. This can be a big delay if the model is large.
- OK, we are ready to go! We finally have the image, the code, the hyperparameters, the model parameter vector(s), other dependent objects... so PyTorch kicks in, the AI describes which parameters to load into the GPU or FPGA, and the "run" button can be pushed (believe it or not, this really is how it looks inside the PyTorch or Tensor Flow runtime). Our AI might be fast -- many computer vision algorithms are remarkably fast. So in 50 or 75ms, we have an answer: the taxi has moved 5.2 meters and is now at this new location.
Notice the absurdity of this: we will probably spend 2 or 3 seconds "preparing" (if not more) all to run an AI task that can finish in 1/20th of a second!
Clearly the answer is that we need a platform able to pull all the necessary objects into one shard, but then to run the AI logic on those same machines. And we need a way to arrange that the compute servers themselves will be physically close to the cameras. Yet, and this is a bit of a contradiction at first glance, we probably also want this to be totally compatible and transparent for existing AIs that normally run on the cloud. After all, there are thousands of important, high value, open source computer vision solutions on the cloud today. Who would want to reimplement them (or even to modify them in small ways)?
This became the core goal of Cascade: solve all of these puzzles, all at the same time. And manage the edge hardware efficiently, too, so that if we share a cluster, it will have a high utilization level. And keep private data secure.
Concept: User defined logic (UDLs) inside the Cascade address space
We already had Cascade up and running as a K/V store, accessible via standard RPC and able to mimic a POSIX file system, a pub-sub system or a DDS. But our new challenge was to avoid losing Cascade's potential speed at the last step.
In a standard deployment of PyTorch, Tensor Flow, Spark/Databricks, MXNet or other AI platforms, what the user does is to ask a cloud application management framework like Kubenetes to launch the application (or a container holding it) one some set of computers -- perhaps, 20 instances, if the storage system happens to have 20 shards. Then each instance can handle the part of the job associated with its particular shard.
This would be painful except that on the cloud, we often have ways to hide delay. One is to batch a huge amount of work and tell the system to do all of it. Delays associated with one task waiting can be masked because some other task will often have some work that can be done in the meanwhile. Iterative computations that run for long periods can cache objects: they do wait at startup, but then their caches warm up and they rarely need to fetch more objects as they iterate towards convergence, often needing hours to reach that point. Thus, the costs of fetching the dependent objects are dwarfed by the longer term compute costs, or hidden by the batching model, and overall throughput and utilization levels are high. ChatBots precompute context information and preload the associated files so that when the cloud sees a query (which will already have been rendered from audio to text), everything needed is already present.
At the edge, focused on snappy response, we don't have these opportunities. With standard tools, we would end up running computation on one set of machines but hosting data on a different set of them. Unless there happens to be enough repetition for the same machines to repeatedly do the same tasks, caching won't help much either.
Cascade gets around this by offering to host the user's AI logic in a portion of its own address space -- or, more accurately, address spaces, because Cascade servers will be running on multiple machines, perhaps even hundreds or thousands of them. Each Cascade server offers to host one or more user-specified programs (we call these UDL for short: user developed logic).
We have two options. The lowest cost, most efficient option loads the UDL as a dynamically linked library (DLL) into the Cascade address space. Obviously, every server will have to do this, and a config file option tells it where to find the DLL. Then the DLL implements a standard API, which we invoke to tell it to initialize itself. This allows it to register "watcher methods": functions that Cascade should call if it sees activity on a particular key, or on a key that extends some specified path prefix. To issue Cascade API requests (like K/V get or put) the UDL a simple API offered by an object we call the Cascade context.
But clearly a UDL would need to be very trusted to use this first option. For a less trusted UDL, we offer a second approach. The idea is identical, but now the URL runs as a docker container. It still links against the same Cascade context object and has the same API. But now the only part of the Cascade address space it can see will be in the form of a shared memory segment dedicated to that particular application, in which Cascade makes objects visible (read-only) using a Linux page remap feature. A second segment lets the user's UDL share objects of its own back to Cascade. No copying occurs, so these shared objects could be very large and yet the only overheads are for tiny RPCs that carry a form of automatically relocatable pointers. We are careful to memory-align our objects and to declare this to the C++ compiler, so parallel MMX operations will work in the normal way.
C++ definitely can support this model. We've tested and confirmed that normal Python and Java, and C# dotnet all can fully support it too, via wrappers. MXNet, PyTorch and Tensor Flow seem happy to run in our hosted environment, too. We don't yet have experience with Spark/Databricks or Julia, but hope to tackle these in 2024.
Concept: End-to-end zero copy
Weijia Song uses the term "end-to-end zero copy" to evoke the image of an application that might have a client system where a photo is captured that then shared this with a Cascade server (if on the same machine using our shared memory approach; if not via RDMA or DPDK). Then the server might store the object using Derecho atomic multicast or persistent replication, all without any memory copying in software (RDMA clearly does do some copying in hardware, but only when source and destination are on different machines). In fact this form of zero copy can even move data into a GPU. We believe that Cascade is the first platform to offer a really comprehensive zero copy design.
Security concerns and solutions
A major concern in many edge computing scenarios is that the AI might encounter sensitive private data. With Cascade, that data can be confined to remain purely on the client compute system (or in memory, in a nearby compute cluster designed specifically to support those clients). With this approach, a GDPR-complient solution should be feasible.
Split computing
Cascade CCL
Derecho, on which Cascade is layered, offers a very efficient version of the famous collective computing library primitives (CCLs). These include AllReduce, MapReduce, and other commonly needed host-parallelism patterns. In 2024 we plan to develop a wrapper integrating the Cascade K/V model (and its end-to-end zero copy properties) with the DCCL package so that we can offer an ultra-efficient CCCL: Cascade CCL.