Title in audio
ASTER Demonstration
 is
dedicated to my Guide-Dog.
AsTeR --Audio System For Technical Readings-- is a computing system for
rendering technical documents in audio. AsTeR was developed by
is
dedicated to my Guide-Dog.
AsTeR --Audio System For Technical Readings-- is a computing system for
rendering technical documents in audio. AsTeR was developed by
 for his
PhD. (141 pages) An audio formatted version of the thesis,
(approximately 6 hours) produced by AsTeR, is being made available by
RFB (Recordings For the Blind
as the first computer generated talking book. Here is the abstract in print, and
here is an audio formatted version.
for his
PhD. (141 pages) An audio formatted version of the thesis,
(approximately 6 hours) produced by AsTeR, is being made available by
RFB (Recordings For the Blind
as the first computer generated talking book. Here is the abstract in print, and
here is an audio formatted version.
This hypertext document demonstrates the audio renderings generated by AsTeR.
Each example is made up of three components:
- The original LaTeX input.
- The audio formatted output produced by AsTeR.
The speech is produced by a Dectalk, and has been digitized at
8-bit mulaw
AsTeR uses stereo to render tables, an effect that is not
conveyed by the
8-bit mono encoding.
- The visually formatted version produced by LaTeX and DVIPS.
Section 1 simple fractions and expressions.
This set of 8 examples demonstrates the use of
voice inflection and pauses to convey grouping of sub-expressions succinctly.
The state of the audio formatter
is a point in audio space.
Here, audio state was varied along a dimension in audio space before rendering
sub-expressions.
This is equivalent to parenthesizing in the visual context.
Section 2 superscripts and subscripts.
To convey subscripts, superscripts, and other visual attributes, AsTeR varies
audio state along a dimension that is
orthogonal to (independent of ) the
dimension used to convey sub-expressions. This allows the nesting of
these mutually independent concepts.
The following
6 examples
demonstrate how superscripts and subscripts are rendered unambiguously.
Section 3 Knuth's examples of fractions and exponents.
These examples are taken verbatim from the TeX Book, by Donald Knuth.
They are used in the TeX Book to demonstrate the power of the TeX layout
operators.
Notice that all of these examples comprise of the same 6 symbols, but are very
different!
AsTeR renders these
7examples
as unambiguously as TeX.
Section 4 A continued fraction.
Moving along a dimension in audio space defines a perceptibly monotonic
change. This notion of perceptible monotonicity is vital in conveying nesting.
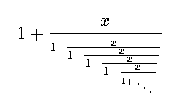 Audio
LaTeX
Postscript
Audio
LaTeX
Postscript
Section 5 Simple School algebra.
Here are
3 examples from school algebra.
Notice the choice of unambiguous renderings for the following
3 expressions:
Section 7 Trigonometric identities.
Written mathematical notation can be ambiguous and hard to recognize.
Notice the complete absence of parenthesis in some of the examples below.
AsTeR uses several heuristics to construct the correct tree structure for
these
7 expressions.
Notice the context-specific rendering of these 4
expressions when speaking the base of the logarithm. The renderings are
chosen to reduce cognitive load; log base a of x
as
opposed to log of x to the base a
Context-specific rendering rules allow AsTeR to interpret the superscripts in
these 5 examples as exponents. Such
interpretation is not hard-wired into the renderings; it is fully customizable
by the user.
The first of these
6 integrals, probably the most innocuous, is also the most
difficult to recognize; it is impossible to determine the variable of
integration.
Here are
3 summations.
Notice that the same expression can be written in more than one way.
Here are
2 limits
Section 13 Cross
referenced equations.
The following
example is meant to illustrate AsTeR's rendering of cross-references, and
is most effective when AsTeR is used interactively.
AsTeR enables the listener to give meaningful names to cross-referenceable
objects, and uses these names when referring to such objects in later
cross-references.
Notice that AsTeR produces good intonational structure when speaking text that
is intermixed with mathematics.
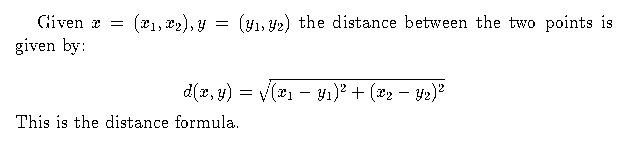 Audio
LaTeX
Postscript
Audio
LaTeX
Postscript
Section 15 Quantified expression.
The quantifiers present an interesting challenge to AsTeR's recognizer.
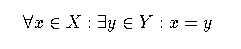 Audio
LaTeX
Postscript
Once again, perceptible monotonicity allows AsTeR to convey the following
3 examples
deeply nested expressions succinctly.
Audio
LaTeX
Postscript
Once again, perceptible monotonicity allows AsTeR to convey the following
3 examples
deeply nested expressions succinctly.
These examples were produced with the Emacs Calculator, a full-fledged
symbolic algebra system.
AsTeR interfaces directly with this calculator, and renders the output just
as well as any document.
AsTeR uses stereo effects to convey the two-dimensional structure of the
matrix. Rendering commences on the left, and moves progressively right as
each element of any row is spoken.
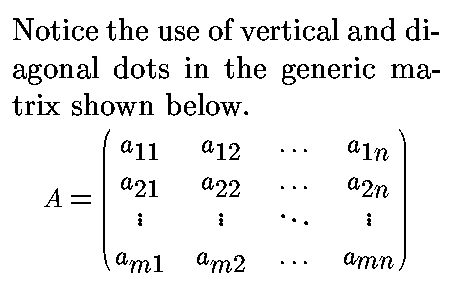 Audio
LaTeX
Postscript
Audio
LaTeX
Postscript
Section 18 Faa de Bruno's formula.
This section presents Faa De Bruno's formula, taken from Knuth's Art Of
Computer Programming, Vol. 1.
I first heard it spoken by a RFB reader on a talking book; it took 120 seconds
to speak.
Since the renderings produced by AsTeR utilize features of the audio space not
available to a human reader (I still have not met a reader who can change the
size and shape of her head as she talks:-) the rendering takes under 80
seconds.
As you will hear soon, even this is too long; you forget the beginning by the
time you hear the end.
Later, we present rendering using variable substitution, a powerful technique
for conveying top-level structure of complex expressions.
AsTeR can process complex expressions like the above, and upon request,
replace complex sub-expressions with meaningful identifiers. Such renderings
convey top-level structure; the listener can then listen to the
sub-expressions separately.
Since this substitution process is performed by AsTeR, there is no LaTeX or
Postscript equivalent for the audio output in this case.
T.V. Raman raman@crl.dec.com
Last modified: Wed Aug 10 19:56:56 1994
 Audio
LaTeX
Postscript
Audio
LaTeX
Postscript
 Audio
LaTeX
Postscript
Audio
LaTeX
Postscript
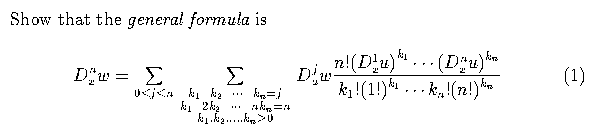 Audio (66 seconds)
LaTeX
Postscript
Audio (66 seconds)
LaTeX
Postscript