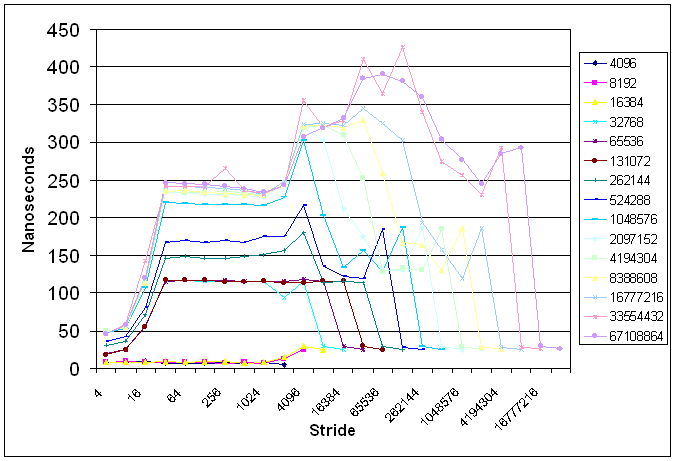
Why, for most sizes >=512k, does the access time spike just before falling to the L1 level (e.g., N=512k and Stride=64k, N=1M and Stride = 128k, etc)? This processor is kinda funny, in that the L2 cache is 512k with 32 byte lines while the TLB is 256k with 4k byte "lines". Both are 4-way set associative. I believe what is happening with these "spikes" is that the data accessed causes conflict misses in the TLB. For instance, for N=512 and Stride=64k, all of the references will fall in the L2 cache without conflict misses, but the TLB can only hold half of the references because of conflicts.
Why does the access time rise to over 400ns for sizes >= 32M? I'm not certain, but I believe that it's because, in the process of handling the TLB miss, a second TLB or L2 miss occurs when the page translation data structures are accessed.
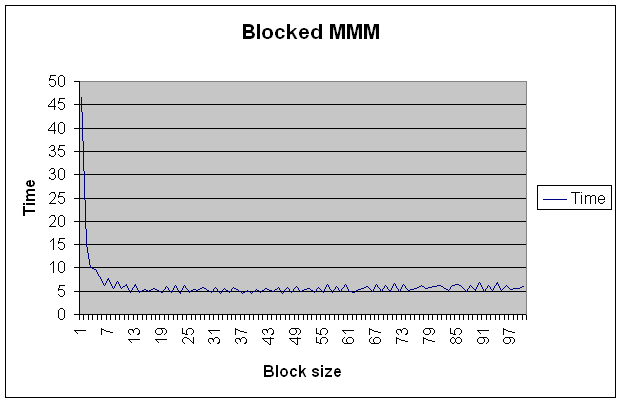
What is the optimal value of K? Here are the 10 best block sizes,
| Block Size | Time |
| 32 | 4.42026 |
| 37 | 4.46711 |
| 39 | 4.48451 |
| 46 | 4.59128 |
| 23 | 4.60884 |
| 34 | 4.61456 |
| 14 | 4.61669 |
| 48 | 4.65089 |
| 30 | 4.67816 |
| 21 | 4.7065 |
Can you explain this value using the memory hierarchy parameters you obtained in the previous problem? The predicted optimal block size is sqrt(16k [L1 cache size]/ (8 [bytes per double] * 3 [three matices])) = 26. In the experiments, K=26 had a time of 5.39342, which is "close" to the best observed value. The difference can probably be explained by the few extra objects referenced by the code and the fact that the experiments were not the only process running on the machine.
The "i->j" version is faster because it traverses the array in the same order in which it is laid out in memory, and thus has spatial locality in the L1 cache. The "j->i" version does not.
Write down a simple loop nest for which interchange would change the computed result.
for (int i=0; i<N; i++)
for (int j=0; j<N; j++)
A[i][j] = A[i+1][j-1] + 1;
Ir - Iw = (i+1,j-1) - (i,j) = (1,-1). Loop interchange would make this (-1,1) which is illegal.
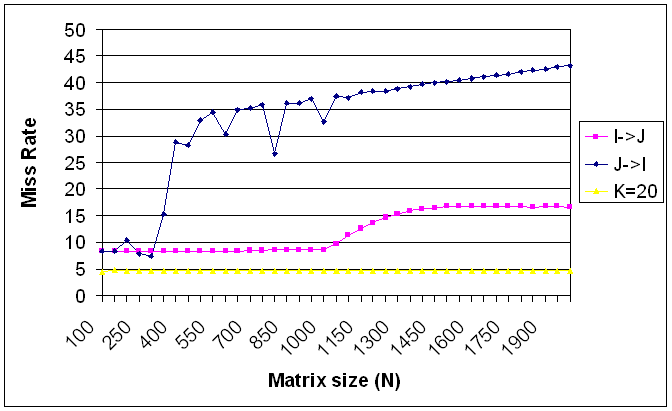
How do your results compare to those presented in class? Is the miss rate constant?
They are consistent with the predicted values. According to the models presented in class, for this cache (c=2k, b=4) the transition from large to small caches occurs at c/2 (1k) for the I->J version, c/(b+1) (about 200) for the J->I version, and should stay constant for the blocked version.
double x=0.0000001, y=1.0; for (int i=0; i<n; i++) y += x * y;
Compiler flags are used to unroll this loop. This is important in order to reduce the overhead of the loop instructions. The computed MFlops are 63.036.
The code for these solutions is available upon request. Just send me email.