Notes on Naming
Lecturer: Professor Fred B. Schneider
Lecture notes by
Lynette I. Millett
In this lecture, we introduce naming, a topic that has rarely
been examined in isolation. As a result, people tend to make common
mistakes with naming when building systems.
Definition
A name is a form of abstraction that
allows us to designate without details. Naming an object permits us
to refer to that object without having to worry about the underlying
details.
Naming is not absolutely necessary; we could live in a world
without naming by using descriptions to refer to objects, but
these descriptions can take time and space. For example, to
fully describe the password file in a Unix system, we would need
to list every user and password in the file! In this case, a
file name provides a much more useful and terse way to refer
to the file.
Properties
Naming should possess the following properties:
- The use of one name does not prevent other names from being
used. For example, naming a file in the current directory shouldn't
prevent you from naming a file in some other directory.
- If an object does not have a name, then it is not accessible.
A name is the only way to denote an object.
- Singular objects do not require names. As an example,
in uniprocessor machines, the single processor was unnamed
and referred to implicitly. However, in
multiprocessor or networked systems, each processor should
have its own name.
Purposes
We can achieve several things by using names:
- Sharing
Different entities can share an object
through its name. If there are two or more processes accessing the
same object, they can set up names and use them to denote the object.
In this case, each entity could use a different name for the same
object.
- Secrecy
Naming can provide secrecy.
In a large name space, usually only a small fraction of
possible names are used. Moreover, it is not
obvious what this fraction will be. An entity
that knows a certain name possesses knowledge that may not
otherwise be available. For example,
computer passwords are typically chosen from a large set of
unguessable character sequences, and provide a mechanism for secrecy.
Binding of names in programming languages also provide secrecy.
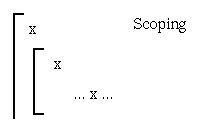 The name of an object in an inner scope masks another object with the
same name from an outer scope.
The name of an object in an inner scope masks another object with the
same name from an outer scope.
Concerns
We now look at some issues regarding naming.
In the past, there had been considerable discussion in the network community
regarding a distinction between names, addresses, and routes. This
distinction actually turns out to be a non-issue. By conventional wisdom,
a name designated an entity, an address denoted its location, and a
route described how to get to that location. For example, in UUCP
(Unix-Unix calling program), a route specifies the sequence of hosts to
contact, e.g. rutgers!princeton!att!fbs. The question of naming
arises in networks. In some cases, the name will also be the
address and the route, e.g. gw2k.cs.cornell.edu.
The current thinking is that such distinctions are specious. Each is
merely a different level of abstraction. In fact, making such sharp
distinctions can cause problems. Consider an Ethernet network.
 Each Ethernet card has a unique address, and it
was common to use the card attached to a processor to name the processor.
The naming fails, however, when two cards are attached to the same
processor, for then, there is the illusion of having two processors. The
two cards provide names, routes and addresses for one CPU and the
distinction is no longer useful.
Each Ethernet card has a unique address, and it
was common to use the card attached to a processor to name the processor.
The naming fails, however, when two cards are attached to the same
processor, for then, there is the illusion of having two processors. The
two cards provide names, routes and addresses for one CPU and the
distinction is no longer useful.
Binding
Names are a way of denoting something, and associated with each name is an
object. This association is called a binding.
Names do not make sense without bindings, and they are always uttered
with respect to a certain context. The meaning of the name
is acquired from the context. A context maps names to objects and has the
following properties:
- The mapping is partial. Consider the use of names for secrecy: only a
small fraction of the name space is used.
- The mapping is subject to change, although it happens slowly and
infrequently. E.g., after a file is edited,
the same file name now refers to a different bit stream.
- The domain of the context is interesting. That is, it may be useful
to determine what is in the domain. We enumerate the names in a domain
or sub-domain when we need to create new, unique names.
A simple example of a context is memory. Memory essentially associates
with each address (name) a value
Where are these contexts? Generally speaking, names must acquire
meaning in one of the following ways:
- Names can have a meaning in a universal context. For example,
a country code followed by a national phone number is a universal
context, under the presumption that calls to Mars do not occur.
- Names could be accompanied with the name of the context within which to
evaluate the name. (For example, working directories for
unqualified file names.)
- We could assume (ensure) that whoever evaluates the name will use the
same context as whoever sent the name. This can lead to unfortunate
situations, however.
Context is another way in which to enforce security. For example,
the name "write" may be bound to different things for different users
depending upon their privileges. Context is thus also a form of
protection.
Implementation of Hierarchical Naming
Recall that naming can be thought of in terms of a hierarchy. The
question becomes how to manage binding? If there is no structure
associated with a particular name then a global service is
necessary. It makes more sense to regard a name such as /a/b/b
as a list of simple names and implement it using a tree.

For example, in the above image, the name a/b/b denotes a leaf object
and circles represent directories or contexts. A hierarchically-structured
name can be regarded as defining a path in the tree.
What if we are trying to merging two organizations, effectively
extending names to the "left"? By simply merging, we create a new
root node, and make the two original trees its left and right children
respectively. The trouble is that none of the old names will work
anymore. We need a way to "jump" over parts of the tree, to equate
the value of a name in a directory with the value of another name in
another directory. Consider the following example:
 A solution is to provide a mapping from the path in the old names to
paths in the new names. When we see an old name starting with a
we map it to ibm/a. Similarly, b is mapped to
ibm/b, c to dec/c, and so on. Generally, we can
map the old name p/n to the new name p'/n'/n. This
technique works provided that we have no duplicate names between the
original two trees. Disk mounting in UNIX systems is an example of
this method. For example, ~users/fbs might be mapped to
/disk1/fbs, while ~users/rz is mapped to
/disk2/rz. Note: the naming trees can actually be merged at
any level.
A solution is to provide a mapping from the path in the old names to
paths in the new names. When we see an old name starting with a
we map it to ibm/a. Similarly, b is mapped to
ibm/b, c to dec/c, and so on. Generally, we can
map the old name p/n to the new name p'/n'/n. This
technique works provided that we have no duplicate names between the
original two trees. Disk mounting in UNIX systems is an example of
this method. For example, ~users/fbs might be mapped to
/disk1/fbs, while ~users/rz is mapped to
/disk2/rz. Note: the naming trees can actually be merged at
any level.