Lecture notes by Tom Roeder and Fred B. Schneider
Cryptographic hash functions are 0-key cryptographic functions. They take a variable-length input and produce a scrambled-looking fixed-length output.
h: var-length input -> fixed-length output
The fixed-length output is sometimes called a digest or hash, and it is normally between 100-1000 bits. It can be thought of as the fingerprint of an given arbitrary-length input bit stream. For instance, looking at today's better known hash functions, we have:
Whether or not a given candidate can serve as a a hash function depends on properties of its output. We would like to the output to be difficult to predict from the input (and from the outputs produced for other inputs); the output should look like a sequence of random bits. This intuition is made precise by listing various properties we might expect of a hash function:
We can see the usefulness of Weak Collision Resistance in the following electronic game. Players A and B communicate across a network. Each player selects a random number; whoever selects the larger number wins. In an asynchronous setting, the naive implementation (pick a number, tell it to the other player), admits cheating---the cheater selects a number only after learning what number the other player has selected. What could prevent such cheating would be some way for each player to commit to a selection without revealing the value of that selection until after both players have made their selections. Now the game's implementation has each player:
So interchangeable input-output pairs are difficult to find. Note that with this property, any interchangeable pair at all is sought.
When properties I -- IV hold, the result is sometimes called a one-way hash function; if properties I -- V hold, then the result is called a collision resistant (one-way) hash function.
We submit that properties III, IV, and V imply that the hash output looks random. A consequence of having these outputs be random is that if the output of a hash function is n bits then the probability of changing input data and not causing a change to the hash output will be 1/2n. This expression is justified as follows. The probability that the ith bit of the hash output has changed is 1/2, since the ith bit divides the set of outputs into two classes (i.e., those that have a 1 in this bit, and those that have a 0). A good hash function will put half the input space into one of these classes and half into the other. Since this partitioning is expected with each of the n bits, the probability of none of them changing is:
1/2 x 1/2 x ... (n times) ... x 1/2 = 1/2n
What we seek of a hash function is called the avalanche property: every input bit affects every output bit. If the avalance property does not hold, then some of the input structure will be reflected in the output, and this may leave the hash open to attack. One way to think about the avalanche property is imagine the hash function taking each input bit, chopping it up, and spreading those pieces out over all the output bits.
Two kinds of cryptographic operations are commonly built with hash functions:
The following protocol uses the MAC function HMAC (defined below) and a shared secret key kAB to allow recepient B to establish the integrity of a message text msg received from A:
A -> B: msg, HMAC(kAB, msg)
B: compute x = HMAC(kAB, msg)
B: check x = received hash
And here is the implementation of HMAC:
HMAC(k,m) = H((k XOR opad), H((k XOR ipad), m))
where opad = (01011010)* and ipad = (00110110)* and H is MD5 or SHA-1, and "," represents catenation. The values for opad and ipad are not arbitrary, but were chosen very carefully to ensure that each input bit of the message affects the bits of the output.
The following challenge-response protocol uses a message digest function MD and a shared secret key kAB to authenticate principal B to A.
A -> B: rA
B -> A: MD(rAkAB)
The idea here is to use a hash function to construct a one-time pad, and XOR the one-time pad with the message.
Recall that a one-time pad is a random bit string that is known only to the sender and receive of the communication. Shannon proved that this method of encryption implements perfect secrecy, but the scheme suffers from obvious practical drawbacks (e.g., the key must be the length of the message, and a new one-time pad must be generated for every message). The idea behind the proof of perfect secrecy is simple: for any encrypted text, you can choose any input and find a key that makes the pair a possible one-time-pad-encrypted message. Thus given only knowledge of the ciphertext (and no knowledge of the key), the plaintext is unrecoverable.
Given a hash function MD, principal A constructs and use a one-time pad for encryption as follows:
b1 := MD(kAB)
b2 := MD(kAB, b1)
b3 := MD(kAB, b2)
...
ciphertext := msg XOR b1 b2 b3 ...
To use this method more than once, we use an initialization vector iv, which is exchanged in the clear at the beginning of the protocol. Then instead of computing b1 as above, A computes:
b1 := MD(kAB, iv)
and then proceeds with the protocol as above. Since initialization vector iv changes the first block, and all the blocks are chained together, the final one-time pad should have no apparent relation with any other one-time pad started with a different starting value for iv.
Note:
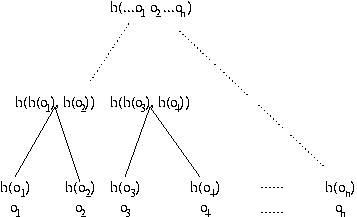
Hashes are very useful for checking authenticity of data, but sometimes the data is so large that we don't want to recompute the hash any time some small part of it changes, since computing hashes for large objects is expensive. The solution is to use a Merkle hash tree, which is a tree of hash values. The value of each node is the hash of the concatenation of its children, or the block itself, if it is a leaf.
So instead of computing n hashes for n blocks, we compute 20 + 21 + 22 + ... + 2log(n) - 1 hashes initially (or equivalently 2*n-1) hashes). And now when we update a block, we need only update those hashes on the path from the node we updated to the root. This means that we only need to compute the height of the tree hash operations. If there are n leaf nodes, then the tree is of height log(n) + 1
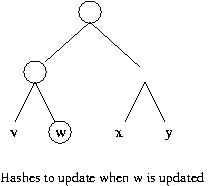
After updating object o2, why not just recompute h( h(o1), h(o2), .... h(on)) using the old values of h(oi) for all objects but oi? This question requires a more careful accounting for the cost of invoking a hash function. This cost is linear in the number of bits of input. To simplify the exposition, suppose all the objects are b bits, and suppose the output of hash function h is bh bits. Thus, the cost of computing the outermost invocation of h in h( h(o1), h(o2), .... h(on)) is n*bh, so after updating an object the total cost of computing a hash over all the data is n*bh+b. With a Merkle hash tree, the total cost is (bh*log n)+ b. Since log n is less than n, the Merkle Hash tree results in a cost savings.
There are three common sources of nonces
The essential risk of 1 and 3 is that they are predictable. This may not matter, depending on your protocol. For example, consider this protocol:
A -> B: r
B -> A: {r}kAB
A -> B: {r}kAB
B -> A: {r + 1}kAB
Since r is never sent in the clear in this protocol, it can be predictable. Even when nonces are allowed to be predictable, sequence numbers have a disadvantage compared to timestamps, since they require you to remember state, whereas for timestamps this function is performed by the clock.