Lecture notes by Lynette I. Millett
Today we will discuss multi-level security (MLS), as an example of MAC. Consider a typical system that uses DAC. Suppose a subject S has access to some highly secret object O. Moreover, suppose that another subject S' does not have access to O, but would like to. What can S' do to gain access? S' can write a program that does two things, the first of which is the following sequence of commands:
A solution to the above problem was proposed by Bell & LaPadula. Their goal was to provide access control for military systems. In the military, documents are labeled according to their sensitivity levels, which range from unclassified (anyone can see this) to confidential to secret and finally (we believe) to top secret.
The military does physical access control on a 'need to know' basis. We have seen this before--it is just the principle of least privilege.
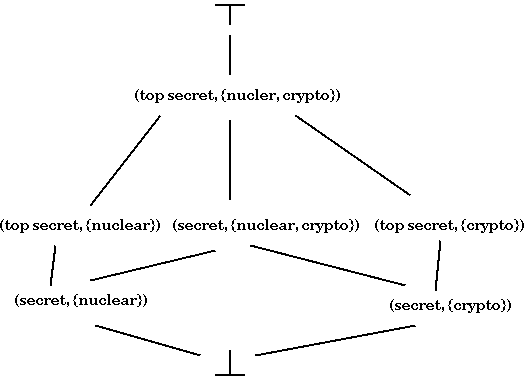
It is not sufficient to use the sensitivity labels to classify objects if one wants to comply with the need to know principle. A given subject may warrant top-secret clearance for cryptology files, but only warrant sensitive clearance for files concerning nuclear weapons.) To handle this decomposition of information, we introduce compartments. Every object is associated with a set of compartments (e.g. crypto, nuclear, biological, reconnaissance, etc.). For example, each paragraph in a document could have pairs associated with it, each pair consisting of a compartment and sensitivity. This provides us with a full classification of a given paragraph for our purposes. The classification of a file might then be the most restrictive classification given to a paragraph in that file.
People are also classified according to their security clearance for each given area/compartment.
Classification labels are of the form (Sr, Sc) where Sr is a sensitivity and Sc is a set of compartments. We say that (Or, Oc) dominates (Sr, Sc) if (Sr, Sc) <= (Or, Oc). This <= relation is true when
We can extend this structure to a lattice. (Recall that in a lattice any two elements have an upper bound and a lower bound.)
Do these rules enforce our need to know principle? We claim that if these rules are followed, then information does not flow from a higher security clearance to a lower one or between incomparable levels. The latter is easy to see, since subjects can only read or write things that are comparable. To demonstrate the former, first note that information flows only if something is first read and then another thing is written. Suppose that object O is read and then object O' is written. This possibility contradicts what we need to prove only if C(O') < C(O). So, we need to show that O' can never be less than O. If a subject reads O we can conclude (from the rules above) that C(O) <= C(S). Similarly, if a subject writes O' we can conclude that C(S) <= C(O'). The dominate relation is transitive and therefore C(O) <= C(O'), as we require.
The above was a significant result when it first was proved. But there are still some problems with this entire scheme.
First, in practice, read and write operations are not atomic, contrary to our assumptions. So, it is possible that the security level for a subject could be changed in mid-operation. This change could violate the information flow constraints we wish to preserve. For example, suppose that a subject has top secret clearance and performs an operation that involves first reading an object labeled (top secret, {x}). The subject then downgrades to the secret clearance level and as part of the operation, writes an object labeled (secret, {y}). In this case, the subject has 'written down' which is forbidden by the rules. We thus need to make sure that subjects do not downgrade security levels in the middle of an operation. Two solutions have been proposed:
A second problem with Bell LaPadula is that this model allows "blind writes." That is, this policy is more concerned with inadvertent disclosure of information to insecure subjects than it is with maintaining the integrity of said information. Subjects can "write up" and not be able to read what's been written, thus, a subject deemed unsuitable for reading an object is permitted to make changes to that object. Moreover, because of this, it is also not possible to do end-to-end checks. One solution is to insist that writes be restricted to the same security level as the subject.
Remote reads are a third source of problems. In a distributed system, communication is done through message passing. Sends and receives provide a way for a user A at one site to read a file on a remote disk B. In this scenario, sends are equivalent to writes and receives to reads. Suppose that A is labeled confidential and B is unclassified. When A sends a message to B, then it is writing down. That is in violation of the rules above. This, even though A should be allowed to read disk B.
Fourth, our scheme also does not say anything about execute privileges. Read and execute are not the same types of access. Complete freedom to execute anything is, again, an instance of trading secrecy for integrity.
Finally, some processes must be allowed to violate the rules about "read up" and "write down". For example, an encryption program, by definition, takes secret information and outputs encrypted but unclassified information. Similarly, to do accounting, programs that may access confidential data produce summary (billing) information that is not confidential. Such programs would seem to be violating the no "write down" restriction. To handle these sorts of cases, we postulate the existence of trusted subjects, which are not subject to the "read up" and "write down" rules. This introduces a potential vulnerability into the system, however. A program masquerading as a trusted subject could, in fact, be a Trojan horse, which is what we were trying to avoid in the first place.
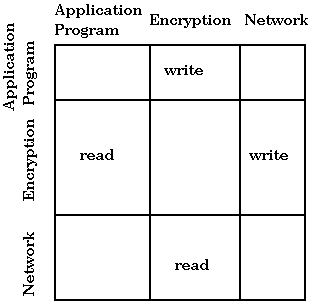
Note that a type enforcement matrix allows us to encode more than a lattice. For example, information flow is not necessarily transitive, and the matrix lets us express this, whereas the lattice does not. Consider the following example: a program sends data to an encryption routine that then sends encrypted data to the network. We would like an application program to be able to write to the encryption routine. The encryption routine should be able to read from the application program and write encrypted data to the network, and the network should be able to read from the encryption routine. The matrix is as follows: