Our training consists of the set $D=\{(\mathbf{x}_1,y_1),\dots,(\mathbf{x}_n,y_n)\}$ drawn from some unknown distribution $P(X,Y)$. Because all pairs are sampled i.i.d., we obtain $$P(D)=P((\mathbf{x}_1,y_1),\dots,(\mathbf{x}_n,y_n))=\Pi_{\alpha=1}^n P(\mathbf{x}_\alpha,y_\alpha).$$ If we do have enough data, we could estimate $P(X,Y)$ similar to the coin example in the previous lecture, where we imagine a gigantic die that has one side for each possible value of $(\mathbf{x},y)$. We can estimate the probability that one specific side comes up through counting: $$\hat P(\mathbf{x},y)=\frac{\sum_{i=1}^{n} I(\mathbf{x}_i = \mathbf{x} \wedge {y}_i = y)}{n},$$ where $I(\mathbf{x}_i=\mathbf{x} \wedge {y}_i=y)=1$ if $\mathbf{x}_i=\mathbf{x}$ and ${y}_i=y$ and 0 otherwise.
Of course, if we are primarily interested in predicting the label $y$ from the features $\mathbf{x}$, we may estimate $P(Y|X)$ directly instead of $P(X,Y)$. We can then use the Bayes Optimal Classifier for a specific $\hat{P}(y|\mathbf{x})$ to make predictions.
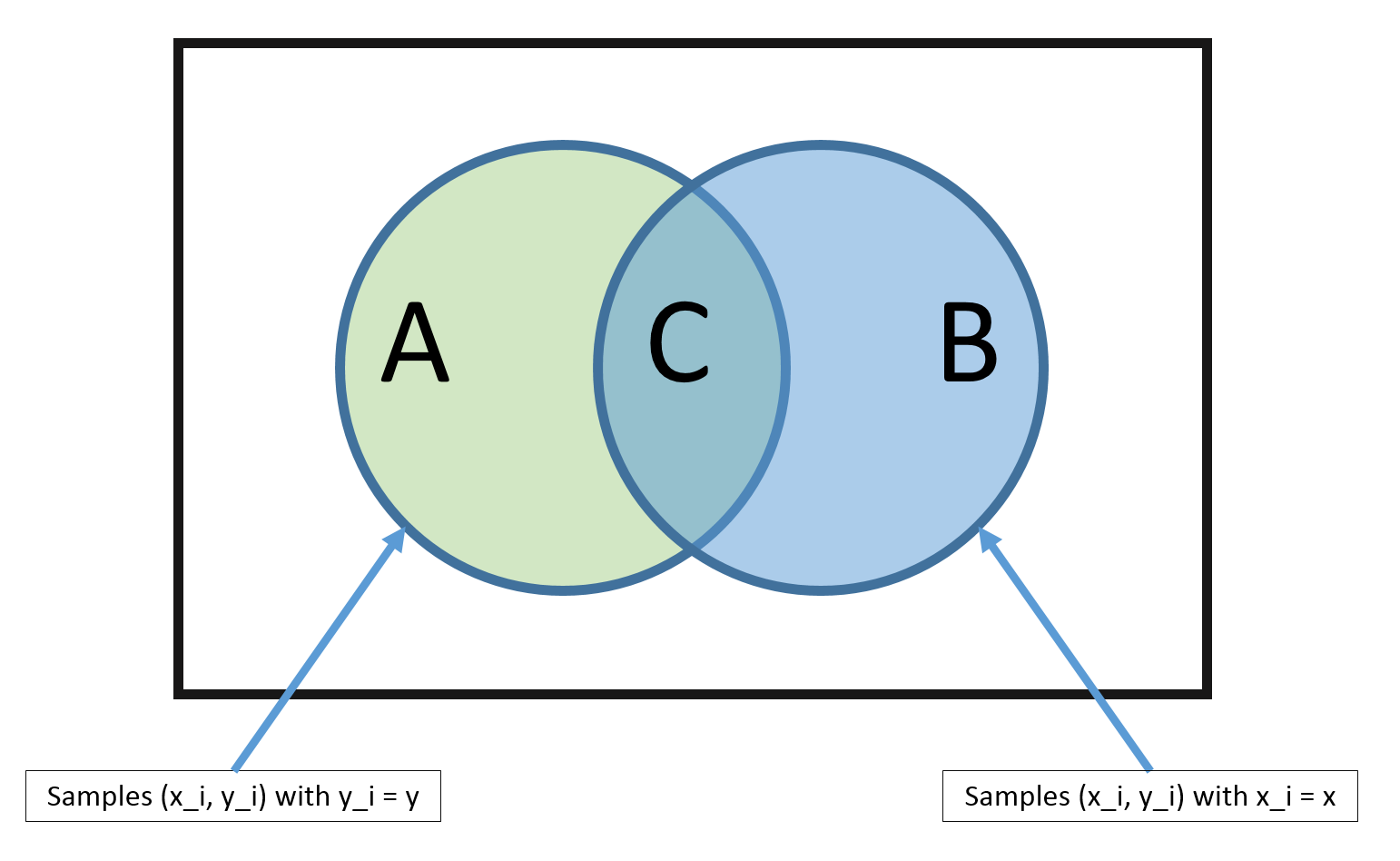
So how can we estimate $\hat{P}(y | \mathbf{x})$? Previously we have derived that $\hat P(y)=\frac{\sum_{i=1}^n I(y_i=y)}{n}$. Similarly, $\hat P(\mathbf{x})=\frac{\sum_{i=1}^n I(\mathbf{x}_i=\mathbf{x})}{n}$ and $\hat P(y,\mathbf{x})=\frac{\sum_{i=1}^{n} I(\mathbf{x}_i = \mathbf{x} \wedge {y}_i = y)}{n}$. We can put these two together $$ \hat{P}(y|\mathbf{x}) = \frac{\hat{P}(y,\mathbf{x})}{P(\mathbf{x})} = \frac{\sum_{i=1}^{n} I(\mathbf{x}_i = \mathbf{x} \wedge {y}_i = y)}{ \sum_{i=1}^{n} I(\mathbf{x}_i = \mathbf{x})} $$
Problem: But there is a big problem with this method. The MLE estimate is only good if there are many training vectors with the same identical features as $\mathbf{x}$! In high dimensional spaces (or with continuous $\mathbf{x}$), this never happens! So $|B| \rightarrow 0$ and $|C| \rightarrow 0$.
We can approach this dilemma with a simple trick, and an additional assumption. The trick part is to estimate $P(y)$ and $P(\mathbf{x} | y)$ instead, since, by Bayes rule,
$$
P(y | \mathbf{x}) = \frac{P(\mathbf{x} | y)P(y)}{P(\mathbf{x})}.
$$
Recall from
Estimating Probabilities from Data
that estimating $P(y)$ and $P(\mathbf{x} | y)$ is called generative learning.
Estimating $P(y)$ is easy. For example, if $Y$ takes on discrete binary values estimating $P(Y)$ reduces to coin tossing. We simply need to count how many times we observe each outcome (in this case each class):
$$P(y = c) = \frac{\sum_{i=1}^{n} I(y_i = c)}{n} = \hat\pi_c
$$
Estimating $P(\mathbf{x}|y)$, however, is not easy! The additional assumption that we make is the Naive Bayes assumption.
Naive Bayes Assumption: $$ P(\mathbf{x} | y) = \prod_{\alpha = 1}^{d} P(x_\alpha | y), \text{where } x_\alpha = [\mathbf{x}]_\alpha \text{ is the value for feature } \alpha $$ i.e., feature values are independent given the label! This is a very bold assumption.For example, a setting where the Naive Bayes classifier is often used is spam filtering. Here, the data is emails and the label is spam or not-spam. The Naive Bayes assumption implies that the words in an email are conditionally independent, given that you know that an email is spam or not. Clearly this is not true. Neither the words of spam or not-spam emails are drawn independently at random. However, the resulting classifiers can work well in practice even if this assumption is violated.
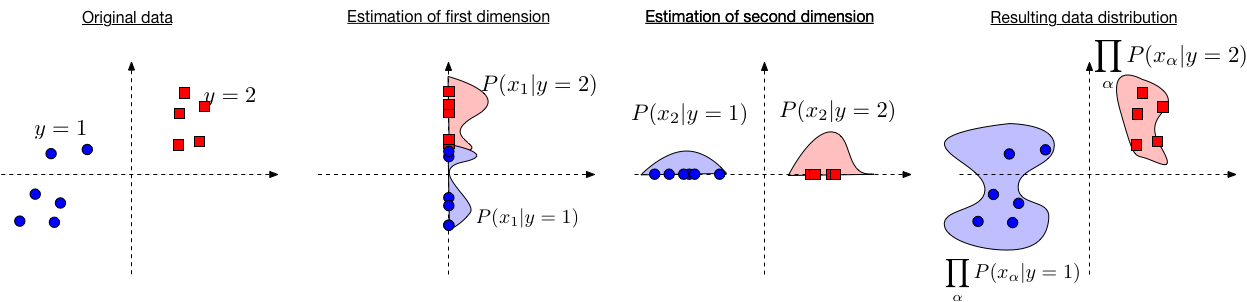
So, for now, let's pretend the Naive Bayes assumption holds. Then the Bayes Classifier can be defined as \begin{align} h(\mathbf{x}) &= \operatorname*{argmax}_y P(y | \mathbf{x}) \\ &= \operatorname*{argmax}_y \; \frac{P(\mathbf{x} | y)P(y)}{P(\mathbf{x})} \\ &= \operatorname*{argmax}_y \; P(\mathbf{x} | y) P(y) && \text{($P(\mathbf{x})$ does not depend on $y$)} \\ &= \operatorname*{argmax}_y \; \prod_{\alpha=1}^{d} P(x_\alpha | y) P(y) && \text{(by the naive Bayes assumption)}\\ &= \operatorname*{argmax}_y \; \sum_{\alpha = 1}^{d} \log(P(x_\alpha | y)) + \log(P(y)) && \text{(as log is a monotonic function)} \end{align}
Estimating $\log(P(x_\alpha | y))$ is easy as we only need to consider one dimension. And estimating $P(y)$ is not affected by the assumption.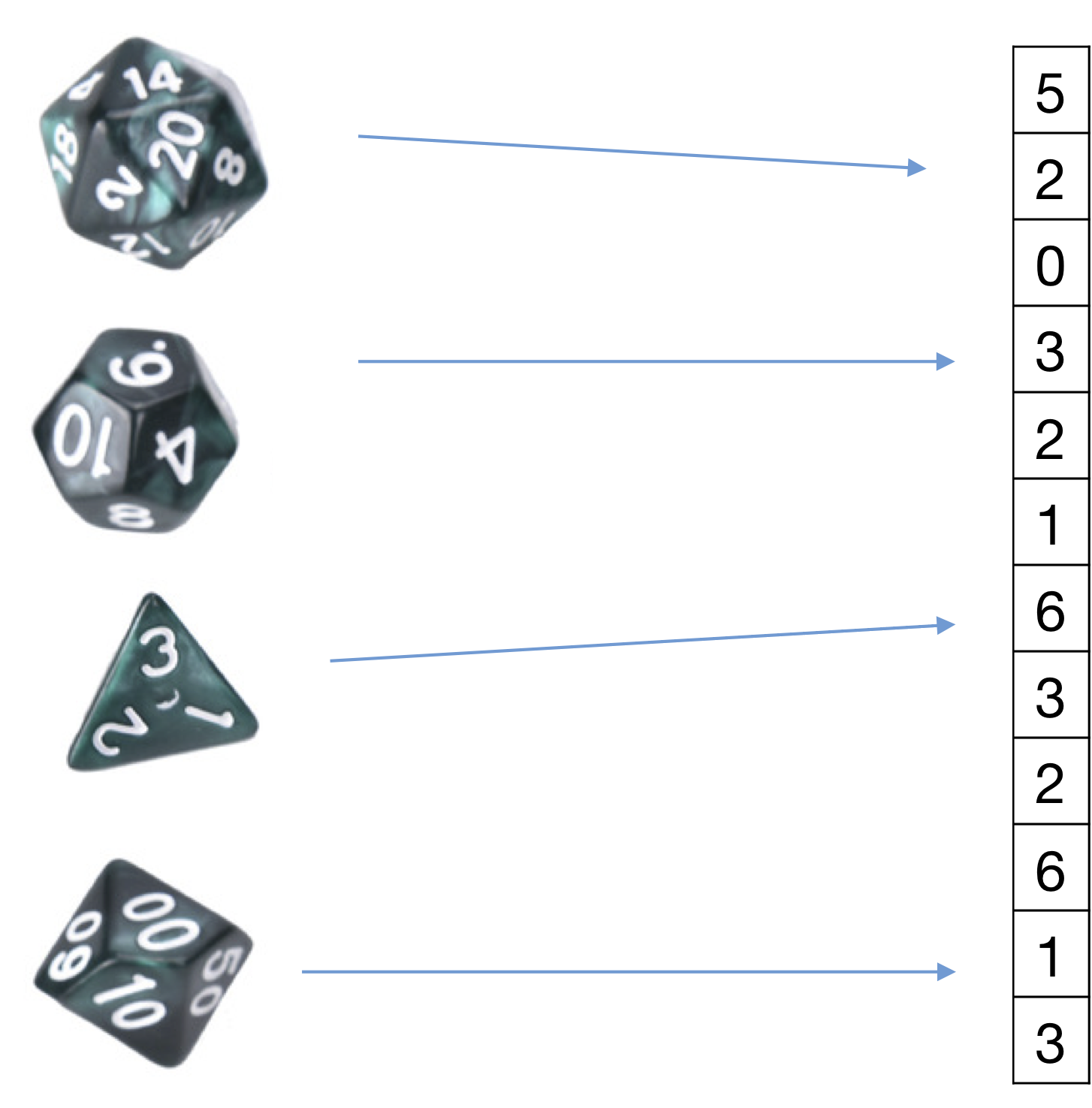 |
In words (without the $l$ hallucinated samples) this means $$ \frac{\text{# of samples with label c that have feature } \alpha \text{ with value $j$ }}{\text{# of samples with label $c$}}. $$ Essentially the categorical feature model associate a special coin with each feature and label. The generative model that we are assuming is that the data was generated by first choosing the label (e.g. "healthy person"). That label comes with a set of $d$ "dice", for each dimension one. The generator picks each die, tosses it and fills in the feature value with the outcome of the coin toss. So if there are $C$ possible labels and $d$ dimensions we are estimating $d\times C$ "dice" from the data. However, per data point only $d$ dice are tossed (one for each dimension). Die $\alpha$ (for any label) has $K_\alpha$ possible "sides". Of course this is not how the data is generated in reality - but it is a modeling assumption that we make. We then learn these models from the data and during test time see which model is more likely given the sample.
Prediction: $$ \operatorname*{argmax}_y \; P(y=c \mid \mathbf{x}) \propto \operatorname*{argmax}_y \; \hat\pi_c \prod_{\alpha = 1}^{d} [\hat\theta_{jc}]_\alpha $$ |
If feature values don't represent categories (e.g. male/female) but counts we need to use a different model. E.g. in the text document categorization, feature value $x_\alpha=j$ means that in this particular document $\mathbf x$ the $\alpha^{th}$ word in my dictionary appears $j$ times. Let us consider the example of spam filtering. Imagine the $\alpha^{th}$ word is indicative towards ``spam''. Then if $x_{\alpha}=10$ means that this email is likely spam (as word $\alpha$ appears 10 times in it). And another email with $x'_{\alpha}=20$ should be even more likely to be spam (as the spammy word appears twice as often). With categorical features this is not guaranteed. It could be that the training set does not contain any email that contain word $\alpha$ exactly 20 times. In this case you would simply get the hallucinated smoothing values for both spam and not-spam - and the signal is lost. We need a model that incorporates our knowledge that features are counts - this will help us during estimation (you don't have to see a training email with exactly the same number of word occurances) and during inference/testing (as you will obtain these monotonicities that one might expect). The multinomial distribution does exactly that.
Features: \begin{align} x_\alpha \in \{0, 1, 2, \dots, m\} \text{ and } m = \sum_{\alpha = 1}^d x_\alpha \end{align} Each feature $\alpha$ represents a count and m is the length of the sequence. An example of this could be the count of a specific word $\alpha$ in a document of length $m$ and $d$ is the size of the vocabulary. Model $P(\mathbf{x} \mid y)$: Use the multinomial distribution $$ P(\mathbf{x} \mid m, y=c) = \frac{m!}{x_1! \cdot x_2! \cdot \dots \cdot x_d!} \prod_{\alpha = 1}^d \left(\theta_{\alpha c}\right)^{x_\alpha} $$ where $\theta_{\alpha c}$ is the probability of selecting $x_\alpha$ and $\sum_{\alpha = 1}^d \theta_{\alpha c} =1$. So, we can use this to generate a spam email, i.e., a document $\mathbf{x}$ of class $y = \text{spam}$ by picking $m$ words independently at random from the vocabulary of $d$ words using $P(\mathbf{x} \mid y = \text{spam})$. Parameter estimation: \begin{align} \hat\theta_{\alpha c} = \frac{\sum_{i = 1}^{n} I(y_i = c) x_{i\alpha} + l}{\sum_{i=1}^{n} I(y_i = c) m_i + l \cdot d } \end{align} where $m_i=\sum_{\beta = 1}^{d} x_{i\beta}$ denotes the number of words in document $i$. The numerator sums up all counts for feature $x_\alpha$ and the denominator sums up all counts of all features across all data points. E.g., $$ \frac{\text{# of times word } \alpha \text{ appears in all spam emails}}{\text{# of words in all spam emails combined}}. $$ Again, $l$ is the smoothing parameter. Prediction: $$ \operatorname*{argmax}_c \; P(y = c \mid \mathbf{x}) \propto \operatorname*{argmax}_c \; \hat\pi_c \prod_{\alpha = 1}^d \hat\theta_{\alpha c}^{x_\alpha} $$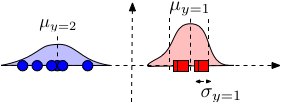 |
Features: \begin{align} x_\alpha \in \mathbb{R} && \text{(each feature takes on a real value)} \end{align}
Model $P(x_\alpha \mid y)$: Use Gaussian distribution \begin{align} P(x_\alpha \mid y=c) = \mathcal{N}\left(\mu_{\alpha c}, \sigma^{2}_{\alpha c}\right) = \frac{1}{\sqrt{2 \pi} \sigma_{\alpha c}} e^{-\frac{1}{2} \left(\frac{x_\alpha - \mu_{\alpha c}}{\sigma_{\alpha c}}\right)^2} \end{align} Note that the model specified above is based on our assumption about the data - that each feature $\alpha$ comes from a class-conditional Gaussian distribution. The full distribution $P(\mathbf{x}|y)\sim \mathcal{N}(\mathbf{\mu}_y,\Sigma_y)$, where $\Sigma_y$ is a diagonal covariance matrix with $[\Sigma_y]_{\alpha,\alpha}=\sigma^2_{\alpha,y}$.
Parameter estimation: As always, we estimate the parameters of the distributions for each dimension and class independently. Gaussian distributions only have two parameters, the mean and variance. The mean $\mu_{\alpha,y}$ is estimated by the average feature value of dimension $\alpha$ from all samples with label $y$. The (squared) standard deviation is simply the variance of this estimate. \begin{align} \mu_{\alpha c} &\leftarrow \frac{1}{n_c} \sum_{i = 1}^{n} I(y_i = c) x_{i\alpha} && \text{where $n_c = \sum_{i=1}^{n} I(y_i = c)$} \\ \sigma_{\alpha c}^2 &\leftarrow \frac{1}{n_c} \sum_{i=1}^{n} I(y_i = c)(x_{i\alpha} - \mu_{\alpha c})^2 \end{align}
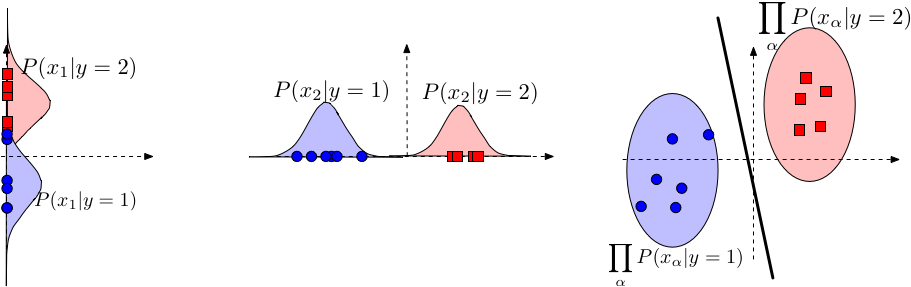
1. Suppose that $y_i \in \{-1, +1\}$ and features are multinomial We can show that $$ h(\mathbf{x}) = \operatorname*{argmax}_y \; P(y) \prod_{\alpha - 1}^d P(x_\alpha \mid y) = \textrm{sign}(\mathbf{w}^\top \mathbf{x} + b) $$ That is, $$ \mathbf{w}^\top \mathbf{x} + b > 0 \Longleftrightarrow h(\mathbf{x}) = +1. $$
As before, we define $P(x_\alpha|y=+1)\propto\theta_{\alpha+}^{x_\alpha}$ and $P(Y=+1)=\pi_+$: \begin{align} [\mathbf{w}]_\alpha &= \log(\theta_{\alpha +}) - \log(\theta_{\alpha -}) \\ b &= \log(\pi_+) - \log(\pi_-) \end{align} If we use the above to do classification, we can compute for $\mathbf{w}^\top \cdot \mathbf{x} + b$
Simplifying this further leads to \begin{align} \mathbf{w}^\top \mathbf{x} + b > 0 &\Longleftrightarrow \sum_{\alpha = 1}^{d} [\mathbf{x}]_\alpha \overbrace{(\log(\theta_{\alpha +}) - \log(\theta_{\alpha -}))}^{[\mathbf{w}]_\alpha} + \overbrace{\log(\pi_+) - \log(\pi_-)}^b > 0 && \text{(Plugging in definition of $\mathbf{w},b$.)}\\ &\Longleftrightarrow \exp\left(\sum_{\alpha = 1}^{d} [\mathbf{x}]_\alpha {(\log(\theta_{\alpha +}) - \log(\theta_{\alpha -}))} + {\log(\pi_+) - \log(\pi_-)} \right)> 1 && \text{(exponentiating both sides)}\\ &\Longleftrightarrow \prod_{\alpha = 1}^{d} \frac{\exp\left( \log\theta_{\alpha +}^{[\mathbf{x}]_\alpha} + \log(\pi_+)\right)} {\exp\left(\log\theta_{\alpha -}^{[\mathbf{x}]_\alpha} + \log(\pi_-)\right)} > 1 && \text{Because $a\log(b)=\log(b^a)$ and $\exp{(a-b)}=\frac{e^a}{e^b}$ operations}\\ &\Longleftrightarrow \prod_{\alpha = 1}^{d} \frac{\theta_{\alpha +}^{[\mathbf{x}]_\alpha} \pi_+} {\theta_{\alpha -}^{[\mathbf{x}]_\alpha} \pi_-} > 1 && \text{Because $\exp(\log(a))=a$ and $e^{a+b}=e^ae^b$}\\ &\Longleftrightarrow \frac{\prod_{\alpha = 1}^{d} P([\mathbf{x}]_\alpha | Y = +1)\pi_+}{\prod_{\alpha =1}^{d}P([\mathbf{x}]_\alpha | Y = -1)\pi_-} > 1 && \text{Because $P([\mathbf{x}]_\alpha | Y = -1)=\theta^{\mathbf{x}]_\alpha}_{\alpha-}$}\\ &\Longleftrightarrow \frac{P(\mathbf{x} | Y = +1)\pi_+}{P(\mathbf{x} | Y = -1)\pi_-} > 1 && \text{By the naive Bayes assumption. }\\ &\Longleftrightarrow \frac{P(Y = +1 |\mathbf{x})}{P( Y = -1|\mathbf{x})}>1 && \text{By Bayes rule (the denominator $P(\mathbf{x})$ cancels out, and $\pi_+=P(Y=+1)$.)} \\ &\Longleftrightarrow P(Y = +1 | \mathbf{x}) > P(Y = -1 | \mathbf{x}) \\ &\Longleftrightarrow \operatorname*{argmax}_y P(Y=y|\mathbf{x})=+1 && \text{i.e. the point $\mathbf{x}$ lies on the positive side of the hyperplane iff Naive Bayes predicts +1} \end{align}
2. In the case of continuous features (Gaussian Naive Bayes), when the variance is independent of the class ($\sigma_{\alpha c}$ is identical for all $c$), we can show that $$ P(y \mid \mathbf{x}) = \frac{1}{1 + e^{-y (\mathbf{w}^\top \mathbf{x} +b) }} $$ This model is also known as logistic regression. NB and LR produce asymptotically the same model if the Naive Bayes assumption holds.