Project 5: Ad-Hoc Networking
Overview
In this project, you will build an ad hoc routing protocol using minithreads, and implement a peer-to-peer instant messaging application.

Ad hoc networks are an emerging new domain. Typically, nodes in wired networks, like the Internet, or infrastructure-based wireless networks, like the 802.11b network on campus, rely on routers embedded in the networking fabric to ferry their data packets to their destinations. For instance, packets to cnn.com are sent out of campus towards CNN's data center by means of Internet routers over fiberoptic links. And a wireless host A that wishes to contact wireless host B does so by going through a base station, which sends the data to the base station closest to B, which ultimately forwards it to B. These approaches work fine today, but have some drawbacks:
- The infrastructure (Internet routers, wireless basestations) requires a large initial investment to set up. If the infrastructure is not set up, there is no way for network participants to communicate.
- The infrastructure is costly and difficult to maintain. These devices require expensive administration for their continued proper operation.
- Problems with the infrastructure lead to catastrophic outage.
Similarly, traditional messaging services, such as AOL IM, MSN messenger, Yahoo messenger and others, suffer from the same drawbacks, for analogous reasons. They rely on a single, expensive data center. Every message sent to every user has to go to this single data center, typically somewhere on the west coast, and get sent back to its destination, even if that destination is your best friend sitting next to you. The goal of this project is to build a peer-to-peer system for routing and messaging that does not suffer from these drawbacks.

Note that two nodes A and B can communicate in the absence of base stations or wired network if there is a chain of wireless nodes between them that are willing to ferry their packets. This sort of network is called an ad-hoc network. The main problems in ad-hoc networking are how to adjust to a changing topology as nodes move around, how to minimize bandwidth consumption due to routing overheads, and how to conserve power. In your routing layer, you will attempt to discover routes as the network changes, and use short routes over longer ones to minimize bandwidth and power consumption. The routing algorithm you have to implement is a simplified version of Dynamic Source Routing (DSR), a reactive ad hoc routing algorithm. The ultimate goal of the project is to have a collection of wireless nodes self-organize, discover routes and ferry data packets to support a peer-to-peer messaging application, without recourse to any fixed infrastructure.
Of course, if you had to set up a wireless network and physically move the nodes in order to test your routing algorithm, you would get tired pretty quickly. And if you had to use a wired network for testing, say a single ethernet segment, you would not be able to exercise the crucial parts of your code; after all, all hosts are visible to all other hosts in one single-hop on an ethernet, and consequently the packet forwarding code would never get tested. That's why we introduce the concept of a network emulation layer in this project. Your minithreads code will use a new layer that emulates a wireless network, even when you are running on a set of wired hosts. This enables you to create an artificial wireless network on a cluster of wired nodes, on which you can thoroughly test your routing layer. This emulation creates a multi-hop network in which a host A needs to go through host B to get to C. If the virtual topology says that host A is not within wireless range of C, then packets from A, even when they are sent as broadcasts and even when A and C are on the same ethernet segment, are not visible to C. Only C's direct neighbors in the virtual topology, e.g. B, can get packets through to C. This enables you to build complex networks for experimentation in this project.
This new network emulation layer is called miniroute. It reads a configuration file that describes the topology of the wireless network to be emulated. If two hosts are not within emulated wireless range of each other, they cannot send packets to each other, even though in reality they may be connected to the same LAN. The miniroute layer introduces two new primitives that you should use. The miniroute_send_pkt primitive allows you to send a unicast packet to a host within wireless range. It has the exact same signature and provides the exact same functionality as the network_send_pkt function that you are already familiar with from previous projects. The network_bcast_packet primitive sends a packet to all hosts within wireless range. Broadcasts are useful for route discovery; that is, to send packets when you are not sure which way they need to be directed. When you know the destination, you should be using the miniroute_send_pkt function to perform a directed unicast, which is more efficient.
The Details

It is crucial that networking stacks interoperate. To interoperate, all projects need to follow some common conventions and follow the same specification. In order for your implementation to interoperate with those of others in the course, we fixed the format of the packet headers you ought to support in this project. The headers and data-types are provided in the header file miniroute.h. These may not be modified, and your implementation should conform to the specification provided in that file.
A packet contains a routing header, communication protocol header(s), and then data, in that order. There are three types of routing packets that have to be supported by the routing protocol:
- Data packets
Data packets contain data from the point of view of the routing layer you are implementing. These data packets may indeed be control packets sent by the minisocket layer; regardless, they are simple data packets as far as the routing layer is concerned.
It has the following fields:
- routing_packet_type
- Must be set to ROUTING_DATA.
- destination
- Contains the network address of the destination machine.
- id
- Ignored for data packets.
- path_len
- Indicates the number of valid elements in the path array (described next).
- path
- An array that contains information about the route this packet has to follow in order to be delivered to the destination. The first element of the array is the network address of the source machine, the second element is the machine the source will forward to message to if it wants to reach the destination, the i'th element contains the network address of the machine the (i-1)'th machine is forwarding the message to. The last entry is the destination address. The data packets should not be processed by any of the higher level communication protocols on hosts other than the endpoints.
- ttl
- Set to MAX_ROUTE_LENGTH initially and decremented each time the packet is forwarded. Packets whose ttl value have reached 0 should not be forwarded, but silently discarded.
- Route discovery packets
The full route a packet has to traverse needs to be specified by the source in the packet header. Nodes that wish to send packets discover these routes through route discovery packets. The route discovery algorithm consists of flooding the network with route discovery packets until the destination is reached. Flooding is achieved by sending the route discovery packet received or initiated on this machine to all the neighbors via broadcast. Each machine that receives a route request adds its address to the route array, thus increasing the length of the route by one, and forwards it on by performing a broadcast. The ttl field should be set to MAX_ROUTE_LENGTH initially. To ensure that the routing discovery packets do not live forever in the network, each forwarding host needs to decrement the ttl field by one. If a packet with ttl value of 0 is received or if the machine is already in the route path (accumulated in the field path) and if the current machine is not the destination, the packet should not be rebroadcasted.
In order for the host to distinguish between route requests, each route discovery request coming from the same machine has to have a different id. Once a route discovery is initiated, the initiator should not wait indefinitely for a response to arrive, since the broadcast route discovery packets may get lost in the network and never arrive at their destination. Consequently, each route discovery initiator should wait about 12-15 seconds for each flood it initiates. If, after three separate attempts to reach the destination, no route response is received, the destination may be presumed to be unreachable, and an error returned to the application.
- Route reply packet
- When a route discovery packet reaches the destination machine, an answer has to be sent back to the source machine. The id of this reply packet has to be identical to the id of the route discovery packet, and the path field should contain the route that the reply packet has to take in order to get back to the sender of the route discovery broadcast. This is essentially the reverse of the route used to get to the target of the route discovery algorithm. For instance, if A is connected to B and B is connected to C but A is not connected to C, then when A tries to discover a route to C, C should send a route reply packet through the path C->B->A. For this, C will have to reverse the route used to discover it, which was A->B->C. The recipient of the route reply, which is A in this example, will then reverse the path one more time to obtain the route from A to C. Nodes that forward route replies should not add themselves to the route field, or modify the packet in any other way (save for the ttl). ttl should be set to MAX_ROUTE_LENGTH initially and decremented every time the packet is forwarded. If ttl has value 0, the message is not forwarded anymore. The destination field is the address of the machine that initiated the route discovery request (A in this example), not the one that sends the reply (which is C). Note that the route discovery packet is forwarded back through the intermediate nodes via unicast, using network_send_pkt().

In order to avoid the costly process of discovering a route for every packet send through the network, you have to implement a route cache with SIZE_OF_ROUTE_CACHE entries. When a message is sent (using the function miniroute_send_pkt), the route cache is consulted. If an entry is found and if the information is not older than 3 seconds, the cached route is used to send the data packet; otherwise the route discovery protocol is executed to find the route to the destination. Route discovery should be synchronous: if discovery needs to be initiated, the thread calling miniroute_send_pkt() should be blocked until the new route is discovered or the discovery is retried three times and times out in all three cases. To be able to purge stale routes from the route cache, you may want to rely on your alarms from project 2 to wake up a handler that eliminates old routes. Note that this 3-second cache timeout is meant solely to simplify your implementation, ease cache management, and help your debugging. A real routing protocol would not time out routes unless errors were detected. It would have some extra packet types to signal errors to the endpoints, perhaps perform local route repair, and purge bad entries from the cache. The three second timeout avoids having to implement any of this, and makes errors obvious by placing a load on the discovery and flooding process.
Important note
You should not use external libraries to implement the hash table for your routing cache. You will need to write the hash table code yourself.
Since every packet in the ad hoc environment has to be routed, you have to replace any previous call to network_send_pkt with a call to miniroute_send_pkt that, as far as the other levels are concerned, provides the same functionality. Also you have to rewrite the network handler routine. This is the place where you want to deal with the routing issues, such as replying to route discovery requests, propagating data packets along the specified path and forwarding discovery and reply packets).
Two new files were added to this project: miniroute.h that contains the header of routing packets and the declaration of function miniroute_send_pkt and file miniroute.c where you have to implement the function. Also you need to change the definition #define BCAST_ENABLED 0 in network.h to 1 to enable the broadcast functions in the networking code we have provided. For debugging, you will probably want to use the emulated wireless network, in which case you have to set the value of the symbol BCAST_USE_TOPOLOGY_FILE to 1.
Broadcasts can be sent by calling network_bcast_pkt, which sends the packet to all accessible nodes. This is a low-level mechanism, like network_send_packet: it does not know about miniports, and broadcast packets are not distinguished from unicast packets at a receiver. For debugging purposes, nodes accessible by a broadcast are defined by the broadcast topology, which is read from the file named by the constant BCAST_TOPOLOGY_FILE in network.h. A sample topology file, topology.txt, illustrates the format, with an adjoining network graph:
saranac heineken dosequis kingfisher tecate .xx.x x.xx. xx... .x..x x..x.
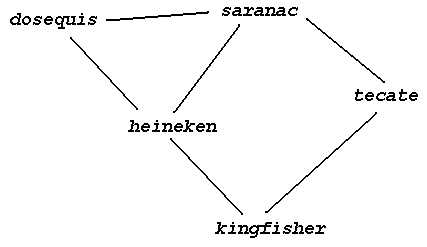
The first section of the topology file gives the names of the computers in the emulated network. After a blank line, the adjacency matrix for broadcasts is given: a dot means there's no link, any other character means there's a link. All links are unidirectional. The diagonal entries are meaningless: whether or not a broadcast at a host is "looped back" and received by the host as well is controlled by the BCAST_LOOPBACK constant, by default there is no loopback. Though each host will read the same matrix, only a host's own row is important when sending broadcasts, the rest are ignored. Note that a broadcast is only sent to adjacent nodes, and does not propagate any further! If "saranac" sends a broadcast, it will reach "dosequis", "heineken" and "tecate", but not "kingfisher", unless it is forwarded by heineken or tecate.
It is also possible to change the topology at a host at runtime, using the network_bcast_add_link and network_bcast_remove_link functions. Changes to the topology are not coordinated between hosts: if tecate removes its link to kingfisher, all the other hosts will have the link recorded. In practice, it doesn't make any sense to remove links for which you're not the source, since it has no effect!

Recall that hosts may have different representations for multi-byte numeric datatypes, e.g. "int"s and "short"s, depending on the byte ordering used in their CPUs. Some CPUs are big-endian, some are little-endian. For instance, x86's use little-endian representation, while StrongARMs may use either little or big-endian representation, depending on the configuration. A large network might contain a mix of big and little-endian nodes. Your code should work correctly on heterogeneous hosts, e.g. a TTL value of 1 should not be interpreted as 4 billion on a host of the wrong-endianness. Consequently, your packet headers, as seen on the wire, should be of a well-known format. Networking people have arbitrarily selected the big-endian format as the wire lingua franca, also known as the network byte order. So, you will have to translate all numeric fields to the network representation. You should use the pack and unpack functions that we have supplied in miniheader.h for translating between the host and network ordering.
This assignment also provides a new device and a new interrupt that enables you to read the keyboard. In addition to the asynchronous interrupt which is invoked every time the user types a line and presses return, we have provided a very simple device driver for you that allows threads to synchronously read the keyboard. Once you have initialized the keyboard device by calling miniterm_initialize(), you can simply call int miniterm_read(char* buffer, int len) to read up to len bytes of keypresses from the keyboard. Keypresses are flushed the moment a newline character has been entered. You should refer to the comments in read.h to find out more about the miniterm_read() function.
The final part of this project involves running your routing code, with minithreads, miniports and minisockets, to send messages from one machine to another without any kind of infrastructure. If your minisockets do not work, you will have to use minimsgs; under no circumstances should you be sending raw (unencapsulated) data packets at the routing layer. You'll need to build a simple interface by which users specify a node and send a one-line message. The recipient should display that message on the screen. Any user-interface, no matter how primitive, will do, as long as it enables the user to specify the destination and payload for the packet.
How to Get Started
Make a backup copy of your code from the previous project, download the code from CMS, and merge.
Submissions
Use CMS to submit your project. You should include a README file with your name, your partner's name, and anything you think we should know. This includes documenting any broken functionality.
Make sure to include all code.
Final Word
If you need help with any part of the assignment, we are here to help.