This assignment is due on November 14, 2006.
In this assignment, you will implement a B+ tree index structure. B+ tree provides an efficient access method for large scale data sets. In addition to reducing query processing time cost, B+ tree can also efficiently manage database catalog (catalog for short), which contains a collection of database file entries, one for each file existing in the database. In fact, in this assignment, the database system can be started in either of two modes depending on how catalog is managed. In one mode, catalog is managed by an instance of B+ tree -- any insertion, deletion, and lookup of file entries will be performed on this B+ tree. In the other mode, catalog is organized by a sequence of file entries -- insertion, deletion, and lookup of file entries will be performed by sequential scans. You will measure the benefit of using B+ tree to manage catalog.
Read the textbook carefully and familiarize yourself with the B+ Tree indexing structure and algorithm.
In the previous two assignments, you were introduced to the Database (DB), Page, HeapPage, HeapFile and Buffer Manager (BufMgr) abstractions. As you may recall, the DB abstraction is responsible for maintaining file entries in the catalog, allocation/deallocation of pages and performing I/Os on the pages. The Page abstraction is just a dummy class of size MAX_SPACE, and HeapPage is a special type of Page. Finally, the BufMgr is responsible for maintaining "frequently" used pages in memory. In this assignment you will have to build a B+ Tree on top of these abstractions.
The class HeapPage has a member called type, which we did not emphasize before. The type of a page is used in this assignment to indicate whether the page is a leaf page or an index page of the B+ Tree.
A SortedPage is a special type of HeapPage that maintains records in a page in increasing sorted order based on a key. Insertion sort is used to insert the records, so the records in a HeapPage may be moved whenever insertion occurs. This may change the RecordID of the records. For this reason, the RecordID of records in a SortedPage should never be exposed to users.
A B+ tree index consists of a collection of records of the form (key, rid), where key is a value for the search key of the index, and rid is the record id of the record being indexed. (It is an index based on what is described as Alternative 2 in the textbook.). In this assignment, you will implement a B+ tree that supports search keys in the data type of NULL-terminated character strings. That is, for a string of k characters, the number of bytes used in the key stored in B+ tree will be k+1, where the k+1th byte is always '\0', The ordering of these strings is based on lexicographical order. For example, "aa" < "ab" < "b".
A B+ tree index is stored in MINIBASE as a database file. The class IndexFile is an abstract class for indices. BTreeFile is a subclass of IndexFile, and implements the B+ tree in MINIBASE.
The class BTreeFile provides methods for inserting, deleting, and searching the tree. The BTreeFile class is responsible for maintaining the integrity of the tree. (i.e. when an insertion is made, it has to ensure that the new record is inserted in the correct place. If the current node does not have enough space to hold the record, it should perform node split.)
The nodes in a B+ tree can be divided into two categories: internal index nodes and leaf nodes. The leaf nodes store the actual (key, rid) pairs, while the internal nodes store (key, pid) pairs, where key and pid denote the key values and the page identifiers (pageIDs) of their children.
The leaf and index nodes in a B+ tree are implemented by the classes BTLeafPage and BTIndexPage, respectively. They are both subclasses of SortedPage and are responsible for inserting into and deleting from leaf node and index node, respectively. These two classes are not responsible for the integrity of the tree.
In MINIBASE, each B+ tree has a header page. The header page is used to hold information about the tree as a whole, such as the page id of the root page, the type of the search key, the (maximum) length of the key field(s). In this assignment, you will implement a B+ tree that indexes over a single string attribute. The header page will therefore only store the page id of the root page. When a B+ tree index is opened, you should read the header page first, and keep it pinned until the file is closed. The header page contains the page id of the root of the tree, and every other page in the tree is accessed through the root page.
The following two figures show examples of how a valid B+ Tree might look.
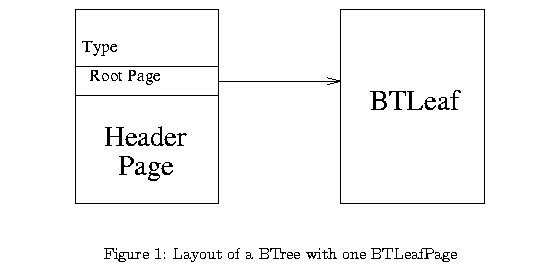
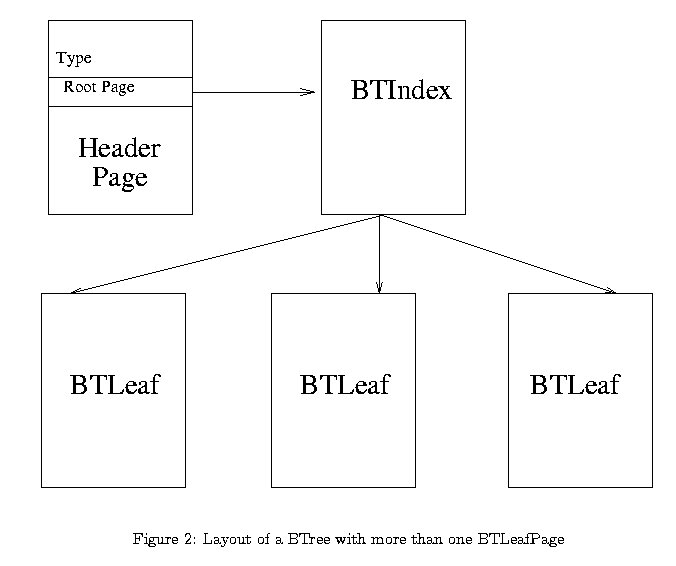
For this assignment, the implementation of BTLeafPage and BTIndexPage are provided for you. We recommend that you study the source code for these two classes carefully. Their implementation can be found in btleaf.cpp and btindex.cpp. You are free to add any methods to these classes that can help with your assignment (try to keep the methods private wherever possible). Do not add any member variables to these classes, since they have to map carefully onto the structure of a page.
Each leaf data item that we insert or delete from a BTreeFile is a tuple (key, record id). These tuples are stored as records of type KeyDataEntry in BTLeafPage. To facilitate a scan through the leaf nodes, the leaf nodes are linked together as a doubly linked list. These "pointers" in the link list are actually PageID of the previous page and next page. The two members corresponding to these pointers are called nextPage and prevPage, which should look familiar to you from the HeapPage assignment. They can be set and retrieved with SetNextPage(), SetPrevPage(), GetNextPage() and GetPrevPage().
Other functions provided for BTLeafPage are Insert and Delete, which, as the names suggest, insert and delete a KeyDataEntry to/from the page. GetNext(), GetFirst() and GetCurrent() are also provided to scan through the records in a BTLeafPage.
The BTIndexPage contains a sequence <pid1, key1, pid2, key2, ..., keyk, pidk+1> (the semantics of this sequence are as described in the textbook). The prevPage member in BTIndexPage (also referred to as the leftlink or the leftmost child page) is used to store pid1 while (keyi, pidi+1) are stored as records of type IndexEntry in the BTIndexPage.
Just like in BTLeafPage, Insert(), Delete(), GetFirst() and GetNext() are provided for this class. It contains some other methods that can be very helpful to your implementation. Read btindex.h and btindex.cpp for their description.
We can also open a scan on a B+ Tree, and retrieve all records within a range of key values. The BTreeFileScan class is a data structure to keep track of the current cursor in the scan. It provides a GetNext() method for retrieving the next record in the BTreeFile. We can also delete the current record at the cursor while we are scanning, using the DeleteCurrent() method.
In this assignment, you are required to implement two classes: BTreeFile and BTFileScan, link them with the rest of the code, and make sure that all test programs run successfully. For simplicity, your implementation does not have to deal with duplicate key values.
The details of the functions that you have to implement are given below. We have also provided some sample code that illustrates the use of the classes we have provided. However, these samples are extremely simple and do not reflect the actual coding that we expect from you. For example, we do not show any error checking in these samples. You are expected to write robust programs by checking the return code and signal errors when necessary.
The constructor for the BTreeFile takes in a filename, and checks if a file with that name already exists in the database. If the file exists, we "open" the file. Otherwise we create a new file with that name.
You can use DB::GetFileEntry() to check if the file exists. A file entry is a pair (filename, pid), where pid is the page id of the "first" page of the file. GetFileEntry() takes in a filename and returns the page id of the first page. In our case, the returned page id should correspond to the page id of the B+ tree header page, stored in BTreeFile member variable BTreeHeaderPage *header.
If no such file is found in the database, GetFileEntry() returns FAIL. We will then need to allocate a new page for the B+ tree header page, initialize the header page appropriately, and create a new file in the database with DB::AddFileEntry() for this B+ tree index file. The root page of the B+ tree is stored in header->root. Since initially the B+ tree is empty, header->root will be set to INVALID_PAGE.
If the B+ tree index file exists in the database, we obtain the page id of the header page, and "open" the file by pinning the header page.
Note there is another constructor of the BTreeFile, which is used for a special B+ tree that manages the database catalog (entries of files in the database). Its implementation has been provided, and you are not required to change it.
The destructor of BTreeFile just "closes" the index. In a correct implementation of B+ tree, only the header page will stay pinned at this point. Therefore you only need to unpin the header page here. Note that it does not delete the file.
This is a static factory method that creates a special B+ tree for managing catalog. The implementation has been provided, and you do not need to modify it. Also, the method is only called in disk space manager (DB class), and should not be called anywhere else.
This method deletes the entire index file from the database. You need to free all pages allocated for this index file. Also, if this B+ tree does not manage catalog (BTreeFile::_bCatalogBTree == false), the file entry in the database needs to be removed (using DB::DeleteFileEntry(filename)). When this B+ tree manages catalog, we do not perform DeleteFileEntry(), since we did not insert a file entry for this special B+ tree into the catalog in the first place.
This method inserts a pair (key, rid) into the B+ tree. The actual pair (key, rid) is inserted into a leaf node. However, this insertion may cause one or more (key, pid) pairs to be inserted into B+ tree index nodes. You should always check to see if the current node has enough space before you insert. If there is not enough space (node overflow), you have to split the current node by creating a new node, and copying some of the data over from the current node to the new node. Note that this could recursively go all the way up to the root, possibly resulting in a split of the root node of the B+ tree. Splitting will cause a new entry to be added in the parent node. In this assignment, you will implement node splitting for handling overflow on inserts. You do not need to implement sibling redistribution on inserts. Note that since we implement string keys, records in B+ tree may have different sizes. Therefore, instead of trying to move half of the records to a new page during sibling redistribution as was suggested by the text book, what you should really do is to try to minimize the difference in space consumption between the two sibling nodes in the redistribution process. Note that with variable length records, in theory it is possible that we cannot split a node even when it overflows (e.g. there is only one record currently in the node, which almost fills up the entire space). However, you do not have to deal with this case, and this case will not occur in the test cases for this assignment.
Splitting of the root node should be considered separately, since if we have a new root, we need to update the B+ tree header page to reflect the changes. Also, if you split a leaf node, be careful in maintaining the linked list of B+ tree leaf nodes.
Due to the complexity of this function, we recommend that you write separate functions for different cases. For example, it is a good idea to write a function to insert into a leaf node, and a function to insert into an index node. The following shows some simplified code fragment that may be helpful.
Checking if there is enough space to insert a record into a leaf node :
if (page->AvailableSpace() ...
Inserting a pair (key, rid) into a leaf node with page ID pid can be done with the following code :
BTLeafPage *page;
RecordID outRid;
MINIBASE_BM->PinPage(pid, (Page *&)page);
page->Insert(key, rid, outRid);
MINIBASE_BM->UnpinPage(pid, DIRTY);
This method deletes an entry (key, rid) from a leaf node. Deletion from a leaf node may cause one or more entries in the index node to be deleted. You should always check if a node underflows (less than 50% full) after deletion. If so, you should perform sibling redistribution, and if that does not work, merge sibling nodes. (read and implement the algorithm in the textbook). Note that with variable length records, in theory it is possible that we can neither redistribute nor merge when a node underflows (e.g. the sibling nodes of this node each have only one record, which almost fills up the entire space). However, you do not have to deal with this case, and this case will not occur in the test cases for this assignment.
For implementing redistribution in this assignment, it is sufficient for you to pick one of the two siblings and try to redistribute. For example, you can always pick the left sibling to perform redistribution; if that fails, try merging; if that fails still, do nothing.
You should consider different scenarios separately (perhaps write separate functions for them). For example, deletion from a leaf node and from an index node should be considered separately. Deletion from the root should also be consider separately (what happens if the root becomes empty after some deletion, but there is still a child node?)
The following code fragment may be helpful :
Checking if a node is half full :
if (page->AvailableSpace() > HEAPPAGE_DATA_SIZE/2)
{
// check if redistribution or merge can occur
}
These methods together implement the search logic of B+ tree. The implementation is provided, and you do not need to modify it. However, you are highly recommended to study them carefully.
This method should create a new BTreeFileScan object and initialize it based on the search range specified. It is useful to find out which leaf node the first record to scan is in.
In this assignment, you are required to collect statistics to reflect the performance of your B+ Tree implementation. This method should print out the following statistics of your B+ Tree.
These statistics should serve you in making sure that your code executes correctly.
These are helper functions that should help you debug, by showing the tree contents. The implementation has been provided, and you do not need to modify it. However, you are highly recommended to study them carefully.
First, note that BTreeFileScan only has a default constructor, which you do not need to implement. Also, a BTreeFileScan object will only be created inside BTreeFile::OpenScan.
The destructor of BTreeFileScan should clean up the necessary things (such as unpinning any pinned pages).
GetNext returns the next record in the B+ Tree in increasing order of key. Basically, GetNext traverses through the link list of leaf nodes, and returns all the records in them that are within the scan range, one at a time.
DeleteCurrent should delete the current record, i.e, the record returned by previous call to GetNext().
Given the complexity of this assignment, you are recommended to also submit a document describing the code that you have written. This will be especially helpful if you submitted code does not pass all the test cases. The document should include assumptions that you made, descriptions of any new classes that you have added, and any other special feature we should take note of. As a guideline, the document should be 2-3 pages long (with normal fonts and spacing), or more, if you feel necessary. If you did not complete the assignment, explain the part that you completed so that we can give partial credits (e.g. our deletion works, except that it will cause your program to fail if an index entry is deleted from the root node.) Show sample test runs that you have used to ensure your code is correct, and explain why they are meaningful.
BTreeDriver::test5() measures the cost of inserting a large number of heap files into the catalog. You are required to measure the time cost of inserting N heap files into the catalog, where N = 5000, 7000, 9000, 11000, 13000, 15000. You should do so for both system modes, where catalog is managed with or without B+ tree. You should put the result in a text file named cost.txt. Optionally, you are to explore a nice graph plotting software called Gnuplot, and use it to plot the performances of these two system modes.
The zip file for the project can be downloaded using the course management system. Once you unzip the file, the directory contains the following files (among others):
| btfile.cpp, btfile.h | code skeleton for the BTreeFile class |
| btleaf.cpp, btleaf.h | code for BTLeafPage class |
| btindex.cpp, btindex.h | code for the BTIndexPage class |
| btfilescan.cpp, btfilescan.h | code skeleton for BTreeFileScan class |
| sortedpage.cpp, sortedpage.h | code for SortedPage class |
| bt.h | general declaration of types |
| btreetest.cpp, btreetest.h | code for manual test interface to the B+ tree |
| btreeDriver.cpp, btreeDriver.h | the B+ tree test cases |
| main.cpp | contains main(), runs tests |
| input/keys.txt | An input file used by one of the B+ test cases. |
You should write most of your code in BTreeFile (.h and .cpp) and BTreeFileScan (.h and .cpp). You can add any member variables and methods to these two classes.
Again, you can also add new methods to the BTLeafPage (.h and .cpp) and BTIndexPage (.h and .cpp) classes (keep these methods private wherever possible). You should not modify any of the other existing methods in BTLeafPage and BTIndexPage. You also should not add any member variables to these classes, since they have to map carefully onto the structure of a page.
You are provided with a component BTreeTest with which you can test B+ tree interactively via standard input. Below are the commands accepted.
| insert <low> <high> | All the records from [low, high) are inserted sequentially |
| scan <low> <high> | Scan for <high> <low> records. |
| delete <low> <high> | Delete records between <high> <low> |
| deletescan <low> <high> | Scan and deleteCurrent records between <high> <low>. |
| Print B+ tree. | |
| stats | Show stats |
| quit (or EOF) | Termination |
Note that <low> and <high> denote integer values. However, they will be converted to strings before being inserted into the B+ tree.
Note that this manual test interface is only provided for your convenience in debugging and testing your code. You should write your code towards passing the test cases in BTreeDriver.
You should submit exactly the same set of files given to you in this assignment, as well as the measurement file cost.txt mentioned above. You can also include the optional project document.
Zip only the above files in your directory and upload them into the course management system by the deadline. No late submissions will be accepted.
This assignment is significantly more difficult than the previous two; not only does it build upon your understanding of the previous two coding assignments (as you must make use of both the Page/HeapPage classes and the Buffer Manager), you are also also called upon to implement a rather intricate data structure. You have roughly three weeks, and you will need them.
FAQ of Assignment 3
Here is a list of frequently asked questions.
Mingsheng Hong
Last
modified:
11/10/2006