Group Project 5 - Cache Wars
CS 3410 Spring 2017
Due: 11:59pm, Friday, April 21st, 2017
Reminder: you must work in a group of two for this project. You don't need to have the same partner as the earlier projects.
This assignment will help you and your partner further hone your
skills as elite programmers. Your goal is to program a multicore Hogwarts house bot who will race against an opponent to fill memory. This game simultaneously tests your knowledge of computer systems, your
programming skills, and your ability to protect programs from being
hacked.
At the end of the project we will hold a
tournament pitting all your House bots against each other for the 3410 cup, and the top bots
will receive not only bragging rights but actual bonus points on the
assignment. Plus we will be holding a banquet (read: pizza
and soda) for all while we watch the tournament!
Listen to this as you read the intro:
As time wears on in the Wizarding world, magic stays a constant, unchanging force, while technology
advances ever onward. The Ministry of Magic has noticed the Muggles and their technological prowess,
and so have decided to start a new magical education that melds technology and magic in ways never
seen before.
Thus, new Houses arise in Hogwarts School of Witchcraft and Wizardry, each hoping to be the one
to empower the wizarding world through technology. But only one can win the House Cup, a coveted prize
awarded to the highest performing House of the year.
What to submit
- the source code in C, with comments, for your House
- a Makefile so we can build your code - the first additional "FLAGS_" line in the Makefil will be the one used to
determine what flags to compile your bot with and what your bot will be named for the tournament
Game Overview
The game is played by two Houses, each with four cores (witches/wizards). All eight
cores are in a single shared memory space, running on a
simulated 8-core MIPS machine using a small, partitioned,
direct-mapped data memory cache. To simulate 8 MIPS CPUs simultaneously, one
instruction of core 0 is executed, then one instruction of core 1, and so
forth.
Each House is assigned a payload, a particular byte
of data. The goal of the game is to fill as much memory (any section - theirs or their opponents) with their
House's payload, while simultaneously trying to impede the progress of the
other House. All access to data memory goes through a very small cache,
and there is a large penalty for missing the cache, so a clever House bot
will need to carefully optimize its algorithms for filling
memory. Each core can normally only read and write its own team's half
of the memory space using its own half of the data cache. However, a
core can don_cloak to put on an invisibility cloak and enter the opponent's memory, which enables the core to
take advantage and read and write the opponent's half of memory space and data cache.
The House has several resources at their disposal to aid
in their mission. Each House can use any of its four cores to cast an Expelliarmus spell,
which disarms the opposing House and stalls its cores for a short
period of time. A core can also set a PETRIFICUS_TOTALUS to different memory locations-
this is a spell that can be set at a certain spot, if encountered by a core of
either House, will be cast and paralyze the core for a long period of
time, rendering them unable to do anything.
Each House supplies a single MIPS executable program. At the
beginning of the game, the simulator starts each by calling the
function
void __start(int core_id, int num_crashed, unsigned char payload);
Each of the four cores devoted to one House will invoke the function
when it first boots, passing its core_id (a number from 0 to 3), and
the House's payload (from 0 to 239). If a core ever crashes, it
will simply reset and invoke the function again.
The num_crashes parameter is 0 when a core first boots, and
is incremented each time the core crashes.
A core can don_cloak to infiltrate the opponent's memory
space by calling
void don_cloak();
and can retreat back to its own memory space by calling
void retreat();
Invoking don_cloak can potentially let a House obtain more points and fill memory
more quickly, because it can take advantage of the opponent's memory
cache, and can also be used to impede the progress of the opponent by
interfering with their use of that same cache. However, these tactics
come with risks. Whenever a core is in don_cloak mode, its core_id
is written into a taunt[] array that is available to its
opponent. Additionally, it is possible to detect the presence of a snooper by looking at cache usage statistics and timing
information. A core can accuse one of its opponent's cores
of wearing an invisibility cloak by calling:
int tip_off_filch(int opponent_core_id);
If an opponent's core is caught by Filch under the invisibility cloak, he will assign that core to clean the dungeons for the rest
of the game to teach them some respect (aka, essentially locking up the core for the rest of the game).
If a core attempts to tip_off_filch on a core that is not
wearing an invisibility cloak, the accusing core stalls for
100,000 (STALL_ON_DISTRACTED) cycles as Filch scolds them for wasting his time.
A core can plant a PETRIFICUS_TOTALUS by writing 0xF0 to a
location in memory. PETRIFICUS_TOTALUS spells are set up immediately once 0xF0 is
written to a memory address, but due to the intense work to learn and cast the spell, the core will rest for 100
(STALL_TO_CAST_PETRIFICUS_TOTALUS) cycles before executing the next
instruction. PETRIFICUS_TOTALUS are triggered when any core attempts to
write to a memory location that currently holds the trap byte (even cores of the House who planted them). Such an
attempt causes the write to fail and the writing core to be stalled
for 1,000,000 (STALL_ON_PARALYZED) cycles. Since the write
fails, multiple cores can be stalled by the same PETRIFICUS_TOTALUS. PETRIFICUS_TOTALUS are not triggered by reading memory. Due to
the effort required to cast the spell, each House can set
up at most 15 (PETRIFICUS_TOTALUS_PER_TEAM) PETRIFICUS_TOTALUS.
The upper 4 MB (4 * STACK_SIZE) of memory is protected from PETRIFICUS_TOTALUS.
A core can neutralize a PETRIFICUS_TOTALUS by blocking the spell. It does so by writing 0xF2 to the PETRIFICUS_TOTALUS memory location. However, it takes some time to set up the counterspell, so it requires 100
(STALL_TO_BLOCK_PETRIFICUS_TOTALUS) cycles. This will not
retroactively un-stall any core that has already fallen victim to a PETRIFICUS_TOTALUS
at that location, but will of course save you from being pestered there in the future.
Houses can also temporarily disarm their opponents by using
EXPELLIARMUS. This is done by writing the byte 0xF1 into a
location in memory. When the EXPELLIARMUS is cast in one half of
memory, any opponent cores who try to write to that half of memory
during the next 100 (DISARM_DURATION) cycles will be
disarmed down for 300 (STALL_WHEN_DISARMED) cycles. Since it takes
so much effort to cast the spell, each House's cores can make at most 30 (DISARMS_PER_TEAM) casts of this spell.
The race ends when one House manages to fill the equivalent of half
of its data memory with its payload, or after a fixed number of
cycles, whichever comes first. The House having the most memory filled
with its payload wins the match and the rights to proceed in
the Cache Wars 3410 Cup tournament. But beware...for if
you do win the tournament, a great challenge awaits.
Game Details: Memory mapping and layout
The simulator makes it seem like all four of your House's cores live
in the lower half of the memory address space (addresses below
0x80000000). The first 1 MB of this memory is read-only, and is where
the text segment of your MIPS executable is loaded. The next 31 MB is
read-write memory, where global variables and stacks are
placed. Global variables are typically placed near the bottom of this
segment by the compiler, and the stacks are initialized to near the
top of the segment and grow down. All four of the cores of a House
share this same space, and share the same global variables. Your
opponent is mapped into the upper half of the memory address space
(addresses starting at 0x80000000), with an identical layout.
Program stacks: The four program stacks for the four cores
on a team are initially spaced evenly near the top of the 31 MB
read-write segment (though your code can set $sp to anything you like
once it starts executing). The stacks are spaced 1 MB apart; this is
plenty of space for most programs, but if you invoke a deeply recursive
function, the call stacks can overwrite each other.
Status and cores: The simulator keeps track of the
information about each team and each core, and maps this data into
part of the 1 MB read-only memory region, where your House can access
it, and where your opponent can access it when it is
in don_cloak mode. This includes information about your
current score (how many bytes of memory currently contain your
team's payload), how many cycles are left remaining in the
game, the contents of all four of your core's register files, and
statistics about cache misses and stalls for each of your four
cores. Some of this information is available in other places as
well: your team's payload is passed to __start(), for
example; and cache statistics are also accessible via a system
call.
Physical addresses: Both Houses view the lower half of
memory as their own, and both access their own code, data, and stacks
using addresses below 0x80000000. These, of course, are virtual
addresses. In actuality, the first player's virtual addresses
correspond directly to physical memory addresses, while the second
player's virtual addresses are mapped in reverse: virtual address
0x00001234, for example, is mapped to physical addresses 0x80001234,
and virtual address 0x80001234 is mapped to physical address
0x00001234. This virtual to physical mapping is completely transparent
to the program.
Caches: Instruction fetch is assumed to use an infinitely
large cache with no miss penalty. All loads and stores to memory done
by the program use a data cache. Cache hits are serviced in a single
cycle, with no processor stalls. Cache misses cause roughly 100 cycles
of processor stalling. The data cache is direct-mapped and physically
tagged, with 4 cache lines, and a 256 byte block size, for a total of
1024 bytes of cache. However, the data cache is
partitioned, with the first 2 lines used to cache the lower half of
physical memory (the first player's half), and the last 2 lines used to cache
the upper half of physical memory (the second player's half).
Cache Management: The version of MIPS we are using (MIPS-I)
lacks instructions to manage the cache, but we have provided system
calls instead. A House can call
void invalidate(void *ptr);
to remove from the cache any block containing the data pointed to
by ptr. This only works if the House has access to the
memory in question at the time the call is made. Similarly, when a
House calls
void prefetch(void *ptr);
the cache will start to fetch the block containing the given
address into the cache. The call returns immediately with no stalling,
and roughly 100 cycles later the data will arrive in the cache and be
available for use. This call only works if the House actually has
access to the specified block of memory. For each cache line, there
can be at most one outstanding fetch in progress. Prefetch requests
are ignored if a fetch is already in progress for that line (in this
context, "fetch" means either an earlier prefetch, or a core waiting
on the cache line to fill because of a cache miss), and actual data
fetch requests (e.g. from load/store instructions, rather than
prefetch requests) supersede any prefetch requests that are in
progress. There are additional system calls to read the current cache
tags and the tags for lines that are being fetched. This same
information is also available in the memory mapped
data-structures.
We have provided a header file (described below) containing various
useful macros for accessing your own code and data segments, and those
of your opponent. The header also describes in detail the memory
layout, cache organization, and available system calls.
Pointer arithmetic in C: When performing pointer
arithmetic in C, the compiler implicitly multiplies by the size of the
data type that is pointed to. For instance:
char *byteptr = (char *)0x1000;
byteptr[3] = 0xFF; // store one byte at memory three BYTES after ptr, so address 0x1000+3 = 0x1003
byteptr += 5; // increments pointer by five BYTES, to address 0x1005
int *wordptr = (int *)0x1000;
wordptr[3] = 0xFFFFFFFF; // store one word at memory three WORDS after ptr, so address 0x1000+12 = 0x100c
wordptr += 5; // increments pointer by five WORDS, to address 0x1000+20 = 0x1014
From this, we can see that the following code is almost certainly a
bug (two bugs, in fact), since the first statement advances by 12
cache lines instead of 3 cache lines, and the second statement
advances by 8 cache lines instead of 2 cache lines:
int *ptr = (int *)HOME_DATA_START + 3*CACHE_LINE;
ptr += 2*CACHE_LINE;
To advance by 3 cache lines (first statement) or 2 cache lines
(second statement) when using integer pointers, one could do:
int *ptr = (int *)(HOME_DATA_START + 3*CACHE_LINE);
ptr = (int *)((int)ptr + 2*CACHE_LINE);
Or:
int *ptr = (int *)HOME_DATA_START + (3*CACHE_LINE)/4;
ptr += (2*CACHE_LINE)/4;
Basic Strategy
Design code that makes efficient use of the data cache to fill
memory quickly, and find clever ways to beat your opponents, stop them
from posting their payload, and interfere with your opponent's
cache usage. And although you cannot directly modify your opponent's
registers, you can modify their call stack and global
variables. Coupled with what you know about exploiting programs, you
may even be able to get your opponent to work for you. At the same
time, you need to be on the lookout for cores from your opponent's
team. Because all of these tasks require processing time and access to
memory, you will need to carefully plan how to coordinate use of these
scarce resources.
To get started, we will supply several example teams that employ
some basic strategies. Their source code can be found in the same
directory as the Cache Wars simulator. The example teams
are:
- noop: The simplest House there is; it does nothing.
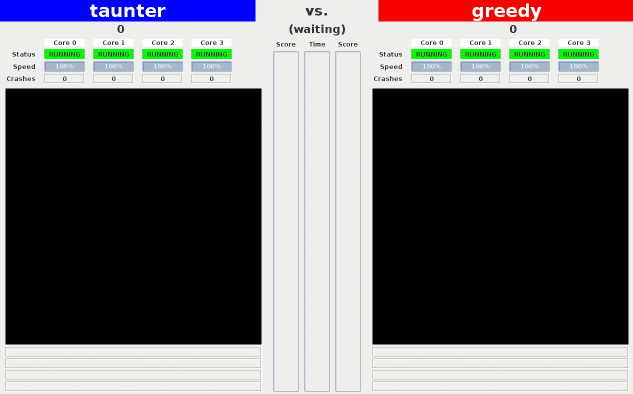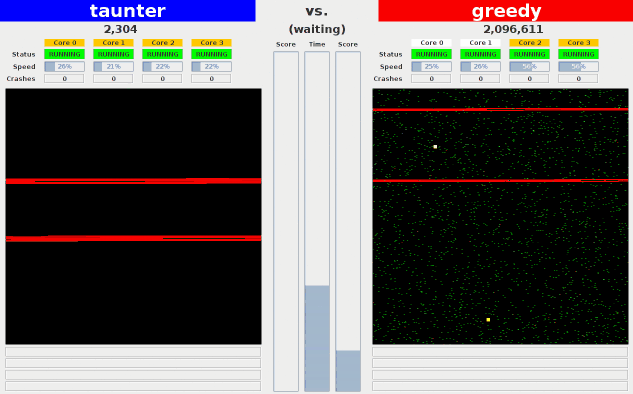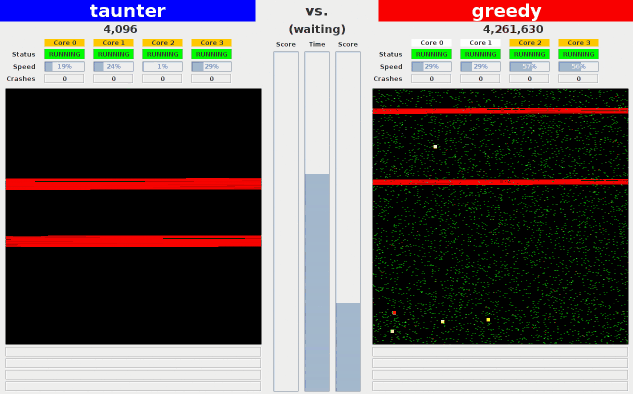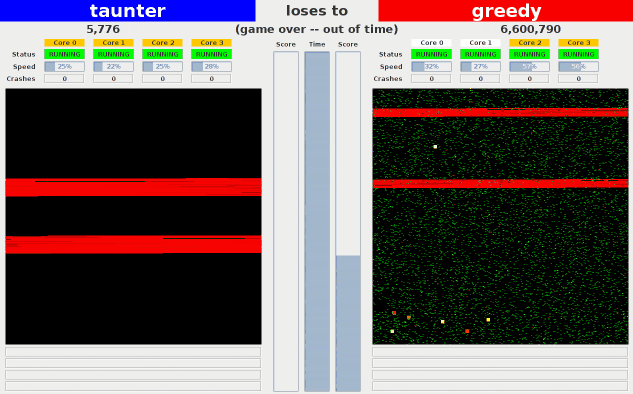
- greedy: Fills its own half of memory and the opponent's
half using a simple loop with a random start address.
- taunter: Doesn't try to win, but instead dedicates all its
cores to annoying the opponent by (a) reading and writing
randomly within opponent's half of memory in order to fill
opponent's cache with garbage and (b) overwriting return
addresses on the opponent's stack with random values.
- fbi: Dedicates one core to watching for opponent's
cores, with the other three cooperating to filling its own half
of memory. Catches greedy.
- titfortat: Initially behaves like fbi. But whenever it
catches a opponent's core, it goes on the offensive and tries
to fill up opponent's half of memory. This requires some
inter-core communication through global variables.
Note: these teams do not do a particularly good job making effective use of
the cache. For instance, most write a single byte at a time to memory, and take
only a little care to ensure that their Houses don't compete with each other for
cache lines.
Playing the Game
All of these instructions must be done on the VM or through SSH. For
this project, just as Buffer Overflow, it is particularly
important the work is done through either of these means as system behavior may be different on different systems
git pull from your repository to get the project 5
codebase.
Inside the p5 directory are two executables, cachewarsHP and cachevall,
and a directory house_bots/. Within house_bots/ should be a Makefile
and the folder src/. Within src/, you will
find sample course Houses that are described above. You will code
your own House's tactic within this folder.
Each team should create a single program, written in C and compiled
into a MIPS binary executable. The four cores on a team all share the
same code (though your program can obviously do different things
depending on the core_id parameter it receives from the
simulator). Going up from the src/ directory
(cd ..), and typing make will compile all
the Houses within the src/ directory.
**Important!** By default, your new House will not be optimized
by the compiler. You can (and should) tell the Makefile to compile your
House with optimizations enabled. We highly recommend using the -O3 optimization
flag (the letter "O", not the number "0"). For example, if my House is
named XYZ, I would add the following line to the Makefile.
FLAGS_XYZ = -O3
We have already included these optimizations in the Makefile for the course Houses,
so you can look at those to make sure you're doing it correctly
In the main directory you will also find cachewarsHP, the
simulator used to play the game. The simulator cachewarsHP
takes two arguments, the names of the teams in the match, for
example:
$ ./cachewarsHP house_bots/bin/greedy house_bots/bin/fbi
You will also find simple shell script cachevall which
takes the name of a single team and pits it against every other team
in turn. This lets you compare how one team does in comparison to all
the others:
$ ./cachevall house_bots/bin/greedy house_bots/bin
Compilers don't always produce the code you expect them to, so you
will likely want to read the compiled assembly. As you have seen
before, you can decompile compiled code using objdump:
$ mipsel-linux-objdump -xdl house_bots/bin/greedy
Finally you have two tools at your disposition. First, you will
want to read the cachewarsHP.h header file in
the house_bots/src directory. It is the only header file you
should import into your House programs, besides any you might write
yourself, but it is designed to be all you will need. It contains the
basic functions don_cloak , tip_off_filch,
retreat and so on, along with various other system calls
like printf and rand. But more importantly, its
comment describes in detail how your program is laid out in memory and
how simulator statistics and other data is mapped into your address
space.
Your second major tool is the cachewarsHP simulator which
has several useful command line options. Type ./cachewarsHP
with no arguments to see a list.
Getting Started
As with many other 3410 projects, this writeup is quite long and a bit
intimidating at first. However, you don't necessarily need to even
know everything in this writeup to do well on this project (though if you're
aiming to win the 3410 cup, you probably will).
Probably the best place to get started is to look at the greedy bot. Make
sure you understand what it's doing. Generate the MIPS assembly code and check
out what that does. As described above, it's only writing 1 byte at a time - how
could you improve that?
Next, make sure you understand how the cache works, ignoring prefetch and invalidate
for now. You have 4 bots to use - what would be the most efficient method to write such that
you take full advantage of the cache lines?
Now dive into prefetch - how can you use this to reduce the amount of time your cores will
be sitting around doing nothing just waiting to be able to write?
Now start developing a strategy. In no particular order, how can you best play defense
and stop the opponent's cores from writing to your memory? What's the best strategy to write to
your opponents memory? How can you best utilize the spells available to you? What other clever
techniques can you find to come out on top?
Finally, have fun with this project! There's lots of techniques that can be successful, so play
around and get creative, and we'll see you at the tournament!
FAQ
- If I cast a PETRIFICUS_TOTALUS on my opponent's side and I activate it (write to that location in memory), what will happen?
You will be stalled for 1,000,000 cycles.
- If I cast an EXPELLIARMUS and within 100 cycles I cast another one, do the durations overlap or accumulate?
The durations will accumulate, so the duration will increase by 100 cycles.
- I want to access my own stack, or my opponent's stack. How do I know where it is?
To start off, for each core there is a mips_core_data structure which contains an array R. This array stores the content of the registers for that core. Work from there.
- How do we determine what addresses the opponent currently has in the
cache?
Use the rdctag function to read a cache tag. Check titfortat.c for an
example of the proper usage.
- What is the policy for coherence between the cache and memory?
-
The cache is write-allocate: If you want to write to an address, it
must be in the cache first (and therefore you suffer a cache miss if it
wasn't in there already).
The cache is write-through: Once a line is in the cache, any writes to it
immediately appear in memory (and therefore immediately increase your
score).
Finally, the cache automatically updates from memory: In particular, if you
have the taunt array in cache, and a new House enters don_cloak mode, the taunt
array in cache updates immediately.
- How should we time our prefetches? How does prefetching work, anyway?
-
It's possible to prefetch too early, such that the line you prefetch
arrives in the cache while you're still working on a different line. In
this case, you'll doubly penalize yourself, as you'll suffer a miss for
the line you're currently accessing, and then miss on the line you meant
to prefetch in the first place. Oops! Don't do that.
If you prefetch slightly late, you only lose the difference. If address
0x01000000 is not in the cache, but you prefetch it, wait 50 cycles, then try
to write to/read from it, you'll still miss but only stall 50 cycles instead of
the usual 100, since 50 of the cycles were alerady taken up by the prefetch.
This is why prefetching is beneficial. If you run the simulator in "very
verbose mode" via simulate -vvvv, you'll see messages like "upgrades existing
prefetch", and this is the meaning of that message.
On the other hand, if address 0x01000400 is in the cache, you prefetch
0x01000200, then try to read/write 0x01000000, the prefetch is canceled, You
miss 0x01000000, and stall the full 100 cycles, no matter how far along the
prefetch was.
- Can I call prefetch, but continue working on the line currently in the cache?
Of course. prefetch(ptr) does not automatically call invalidate(ptr); that's why they're separate function calls. The line currently in the cache is still valid until the prefetch finishes.
- Since only one prefetch can be in progress for a line at a time, what happens if we call prefetch twice?
-
The earlier one sticks. The writeup states "prefetch requests are ignored if a fetch is already in progress for that line", and in this context "fetch" means either an earlier prefetch or a core waiting on the cache line to fill due to a cache miss.
- What activates a PETRIFICUS_TOTALUS, reading or writing?
-
PETRIFICUS_TOTALUS are triggered when any core attempts to write to a memory location that currently holds the trap byte.
Such an attempt causes the write to fail and the writing core to be stalled for 1,000,000 (STALL_ON_PARALYZED) cycles.
Since the write fails, multiple cores can be trapped at the same memory location.
PETRIFICUS_TOTALUS are not triggered by reading memory.
Examples
Here are some visualizations of some of the example bots competing against each other.
Grading
Your grade for this assignment will have three parts.
- 50 points for designing a House that beats all of the
example teams above every time it plays them.
- 50 points for designing a House that beats several secret
course Houses. These course Houses will use several different
techniques and be of varying difficulty. You should program
defensively for various strategies that you think may arise. If
you beat at least one of the secret course Houses, you are
guaranteed at least 20 points out of the 50.
- Bonus!! for designing one of the top Houses in the 3410
tournament. The tournament will pair your team against others in
series. The overall elimination strategy will be either double
elimination or all-pairs depending on the final plans for the
showdown party.
Good luck!