One of the most important and useful algorithms is Dijkstra's shortest path algorithm, a greedy algorithm that efficiently finds shortest paths in a graph. (About pronunciation: "Dijkstra" is Dutch and starts out like "dike").
Because graphs are able to represent many things, many problems can be cast as shortest-path problems, making this algorithm a powerful and general tool. For example, Dijkstra's algorithm is a good way to implement a service like MapQuest, which finds the shortest way to drive between two points on the map. It can also be used to solve problems like network routing, where the goal is to find the shortest path for data packets to take through a switching network. It is also used in more general search algorithms for a variety of problems ranging from automated circuit layout to speech recognition.
Recall that a graph is composed of vertices (a.k.a. nodes) and edges. The shortest path problem is defined on weighted, directed graphs in which each edge has both a weight and a direction. We can think of the weight of an edge as the distance one must travel when going along that edge. For many routing problems, two vertices will be connected by a pair of edges, one going in each direction.
| <% ShowSMLFile("src/wgraph.sig") %> |
There are some constraints on the running time of certain operations in this specification. Importantly, we assume that given a vertex, we can traverse the outgoing edges in constant time per edge. Not all graph implementations do not have these properties (an adjacency matrix does not), but an adjacency list representation like the following does:
| <% ShowSMLFile("src/wgraph.sml") %> |
A path through the graph is a sequence (v1, ..., vn) such that the graph contains an edge e1 going from v1 to v2, an edge e2 going from v2 to v3, and so on. That is, all the edges must be traversed in the forward direction. The length of a path in a weighted graph is the sum of the weights along these edges e1, ..., en−1. We call this property "length" even though for some graphs it may represent some other quantity: for example, money or time.
To implement MapQuest, we need to solve the following shortest-path problem:
Given two vertices v and v', what is the shortest path through the graph that goes from v to v' ? That is, the path for which summing up the weights along all the edges from v to v' results in the smallest sum possible.
Clearly we can solve this problem by solving a more general problem, the single-source shortest-path problem:
Given a vertex v, what is the length of the shortest path from v to every vertex v' in the graph?
It is this problem that we will now investigate. Although this algorithm appears less efficient than simply finding the shortest path to the desired destination, it can be terminated early once the desired destination is found.
The single-source shortest path problem can also be formulated on an undirected graph; however, it is most easily solved by converting the undirected graph into a directed graph with twice as many edges, and then running the algorithm for directed graphs. There are other shortest-path problems of interest, such as the all-pairs shortest-path problem: find the lengths of shortest paths between all possible source–destination pairs. The Floyd-Warshall algorithm is a good way to solve that problem efficiently.
Let's consider a simpler problem: solving the single-source shortest path problem for an unweighted directed graph. In this case we are trying to find the smallest number of edges that must be traversed in order to get to every vertex in the graph. This is the same problem as solving the weighted version where all the weights happen to be 1.
Do we know an algorithm for determining this? Yes: breadth-first search. The running time of that algorithm is O(V+E) where V is the number of vertices and E is the number of edges, because it pushes each reachable vertex onto the queue and considers each outgoing edge from it once. There can't be any faster algorithm for solving this problem, because in general the algorithm must at least look at the entire graph, which has size O(V+E).
We saw in recitation that we could express both breadth-first and depth-first search with the same simple algorithm that varied just in the order in which vertices are removed from the queue. We just need an efficient implementation of sets to keep track of the vertices we have visited already. A hash table fits the bill perfectly with its O(1) amortized run time for all operations. Here is an imperative graph search algorithm that takes a source vertex v0 and performs graph search outward from it:
| <% ShowSMLFile("src/traversal1.sml") %> |
This code implicitly divides the set of vertices into three sets:
Except for the initial vertex v0,
the vertices in set 2 are always neighbors of vertices in set 1. Thus, the
queued vertices form a frontier in the graph, separating sets 1 and 3. The expand
function moves a frontier vertex into the completed set and then expands the
frontier to include any previously unseen neighbors of the new frontier vertex.
dequeue
function, which selects a vertex from a queue. If q is a FIFO
queue, we do a breadth-first search of the graph. If q is a LIFO
queue, we do a depth-first search.
If the graph is unweighted, we can use a FIFO queue and keep track of
the number of edges taken to get to a particular node. We augment the visited
set to keep track of the number of edges traversed from v0;
it becomes a map dist from vertices to edge counts (ints), possibly
implemented as a hash table (an even more imperative alternative is to store
distances directly in the vertices).
The only algorithmic modification needed is in expand, which adds to the
frontier a newly found vertex at a distance one greater than that of its
neighbor already in the frontier:
| <% ShowSMLFile("src/traversal2.sml") %> |
Now we can generalize to the problem of computing the shortest path between
two vertices in a weighted graph. We can solve this problem by making minor
modifications to the BFS algorithm for shortest paths in unweighted graphs. As
in that algorithm, we keep a visited map that maps vertices to their distances
from the source vertex v0. We
change expand so that instead of adding 1 to the distance, its adds
the weight of the edge traversed. Furthermore, when we find an already visited
vertex, we update its distance only if the new distance is less than the old
distance. Here is a first cut at an algorithm:
| <% ShowSMLFile("src/traversal3.sml") %> |
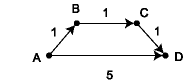
This is nearly Dijkstra's algorithm, but it doesn't work. To see why, consider the following graph, where the source vertex is v0 = A.
The first pass of the algorithm will add vertices B and D to the map visited,
with distances 1 and 5 respectively. D will then become part of the completed
set with distance 5. Yet there is a path from A to D with the shorter length 3.
We need two fixes to the algorithm just presented:
SOME case a check is needed to see whether the path
just discovered to the vertex v' is an improvement on the
previously discovered path (which had length d)q should not be a FIFO queue. Instead, it should be a priority
queue where the priorities of the vertices in the queue are their
distances recorded in visited. That is, dequeue(q) should be a
priority queue extract_min operation that removes the vertex
with the smallest distance.incr_priority(q,v)
that increases the priority of an element v already in the
queue q. This new operation is easily implemented for heaps
using the same bubbling-up algorithm used when performing heap insertions.With these two modifications, we have Dijkstra's single-source shortest path algorithm:
| <% ShowSMLFile("src/traversal5.sml") %> |
There are two natural questions to ask at this point: Does it work? How fast is it?
Every time the main loop executes, one vertex is extracted from the queue.
Assuming that there are V vertices in the
graph, the queue may contain O(V)
vertices. Each extract_min operation takes O(lg V)
time assuming the heap implementation of priority queues. So the total time
required to execute the main loop itself is O(V
lg V). In addition, we must consider the time spent in the
function expand, which applies the function handle_edge
to each outgoing edge. Because expand is only called once per
vertex, handle_edge is only called once per edge. It might call insert(v'),
but there can be at most V such calls
during the entire execution, so the total cost of that case arm is at most O(V
lg V). The other case arm may be called O(E)
times, however, and each call to increase_priority takes O(lg
V) time with the heap implementation. Therefore the total run time
is O(V lg V + E lg V),
which is O(E lg V) because V
is O(E) assuming a connected graph.
There is a more complicated priority-queue implementation called a Fibonacci heap that implements
incr_priorityin O(1) time, so that the asymptotic complexity of Dijkstra's algorithm becomes O(V lg V + E). However, this bound is largely of theoretical interest because large constant factors make Fibonacci heaps impractical for most uses.
Each time that expand is called, a vertex is moved from the
frontier set to the completed set. Dijkstra's algorithm is an example of a greedy
algorithm, because it just chooses the closest frontier vertex at every
step. In a greedy algorithm, a locally optimal, "greedy" step turns out to
lead to a globally optimum. We can see that this algorithm finds the shortest-path
distances in the graph example above, because it will successively move B and C
into the completed set, before D, and thus D's recorded distance has been
correctly set to 3 before it is selected by the priority queue.
The algorithm works because it maintains a loop invariant that
holds every time the while loop is executed:
For every visited vertex v, the recorded distance (in visited) is the
shortest-path distance to that vertex from v0,
considering just the paths that traverse only completed vertices and the
vertex v itself. We will call these paths
internal paths.
This invariant obviously holds when the main loop starts, because the only visited vertex is v0 itself, at recorded distance 0. If the invariant holds when the algorithm terminates, the algorithm works correctly, because all vertices are completed and all paths are internal paths. To show that the algorithm works, we need to show that the algorithm terminates and that each iteration of the main loop preserves the invariant.
Clearly the algorithm terminates, because a vertex can only be inserted once and every loop removes some vertex from the frontier. Showing the invariant is preserved is more interesting.
Each step of the main loop takes the closest frontier vertex v and promotes it to the completed set. For the invariant to be maintained, it must be the case that the recorded distance for the closest frontier vertex is also the shortest internal-path distance to that vertex. However, adding v to the completed set creates no new internal paths to v, so the existing distance must still be the best internal-path distance.
We need to show that the invariant holds on all the other visited vertices too. To show this we begin by observing that the recorded distance to the vertex that is removed from the priority queue can never decrease from one loop iteration to the next; that is, executing the loop can only increase the priority of the minimum-priority element in the queue. Consider what happens during one execution of the loop. Extracting the minimum element clearly leaves behind elements that have distances at least as large. One iteration may add some new elements to the queue, but at distances no less than that of the vertex just removed. It may also reduce the distance estimate to some elements already in the queue, but the new distance estimate will also be no less than that of the vertex just removed.
Now let us consider what happens to the shortest internal-path distance to
some other vertex v′. The new shortest internal path is either the old
shortest internal path (if any), or a path that goes through
v. If the last step on the new path before
reaching v′ is some vertex
v′′ that is not
v, then it must be a vertex that was
completed earlier. By the monotonicity argument, the best path that goes through
v to v′′
cannot be any better than the previously existing path to
v′′ that didn't go through
v. Therefore, the corresponding new internal path to
v′ that goes through v
can't be any better than the old one. The only way that a new shortest internal path
can be created to a vertex v′ is if the
immediately previous node on the path is v′
itself. But if we consider what the code does, we see that
it is comparing these
two candidates for best internal path: the best previously internal path (whose
length is already stored in dist, according to our invariant) and the
best internal path that goes through v.
(Note that if v′ is previously unvisited,
then there is no previous internal path, so the one through
v must be the best!)
We might be concerned that incr_priority could be called on
a vertex that is not in the priority queue at all. But this can't happen because
incr_priority is only called if a shorter path has been found to a
completed vertex v′. Because of the
monotonic increase in distances, this shorter path cannot exist.
The invariant implies that we can use Dijkstra's algorithm a little more efficiently to solve the simple shortest-path problem in which we're interested only in a particular destination vertex. Once that vertex is dequeued from the priority queue, the traversal can be halted because its recorded distance is correct. Thus, to find the distance to a vertex v the traversal only needs to visit the graph vertices that are at least as close to the source as v is.
If we are trying to find a path to a particular vertex, we can often do better than the algorithm described above. The algorithm above visits nodes in order of increasing distance from the initial vertex. Imagine trying to implement the MapQuest service: this algorithm will spend time exploring nodes that are in the opposite direction from the desired goal—nodes that are almost certainly not going be on the optimal path to the destination.
The A* search algorithm (pronounced “A-star”) is a refinement to the shortest path algorithm that directs the search towards the desired goal rather than exploring nodes based simply on distance from the initial vertex. This is useful for implementing services like MapQuest but also for many other problems. The key idea is to define a heuristic function h(v) that estimates how far a given vertex v is from the goal vertex. Rather than just trying to minimize the distance from the initial vertex, we then run Dijkstra's shortest path algorithm with the notion of distance defined as the sum of the real distance and the heuristic function. That is, when picking a vertex to dequeue, rather than choosing the current minimum distance, the algorithm chooses the vertex that minimizes this sum.
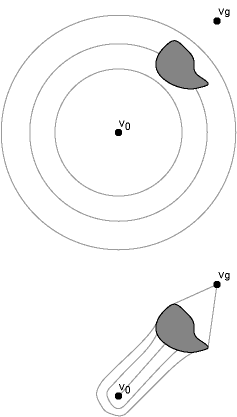
Imagine what happens if the heuristic function is perfectly accurate. In this case, all of the nodes along the optimum path have exactly the same value for distance+heuristic. Therefore they will be dequeued sequentially off the priority queue without any other nodes being considered, because at every step a node on the path will be the current minimum. So the optimal path will be found as efficiently as is possible. Of couse, perfectly accurate heuristic functions are not feasible in general. But even an approximately correct heuristic function can improve search performance dramatically. It is helpful to visualize the shape of the frontier constructed by the ordinary Dijkstra's algorithm versus A* with a good heuristic function. In the latter case the frontier will stretch out towards the goal, as shown in this picture showing the successive exploration by Dijkstra and A* on the plane, using a Euclidean distance heuristic. Here the direct path to the goal vertex is blocked by a gray object. Dijkstra's algorithm will explore concentric circles around the source; A* will explore progressively larger ellipses with foci at the source and destination.
Ideally, a heuristic function satisfies two properties:
In practice, for some search problems it is necessary to sacrifice monotonicity and even admissibility. If this is the case, then the shortest-path algorithm must be modified in the following way to ensure that the optimum path is found: when a shorter path is found to an already visited node, that node must be pushed back onto the priority queue.
A* search is useful not only for motion planning and path finding problems, but also for more general single-player search problems where one might think to use a depth-first search instead. A* can be much more efficient with a good heuristic function, though it tends to use a lot more memory than DFS. (There are also depth-first search techniques that exploit the same insight as A*.)
Cormen, Leiserson, and Rivest. Introduction to Algorithms.
Aho, Hopcroft, Ullman. Data Structures and Algorithms.