|
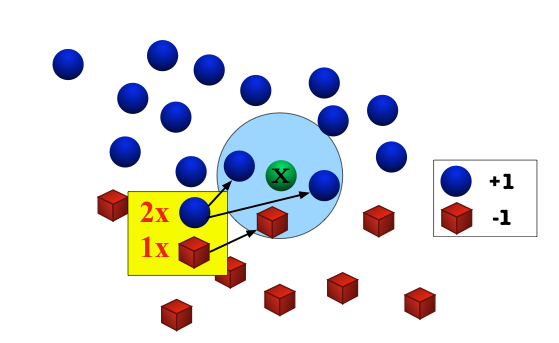
Quiz#1: How does \(k\) affect the classifier? What happens if \(k=n\)? What if \(k =1\)?
The \(k\)NN classifier is still widely used today, but often with learned metrics. For more information on metric learning check out the Large Margin Nearest Neighbors (LMNN) algorithm to learn a pseudo-metric (nowadays also known as the triplet loss) or FaceNet for face verification.
Example: Assume (and this is almost never the case) you knew \(\mathrm{P}(y|\mathbf{x})\), then you would simply predict the most likely label. \[ \text{The Bayes optimal classifier predicts:}\ y^* = h_\mathrm{opt}(\mathbf{x}) = \operatorname*{argmax}_y P(y|\mathbf{x}) \] Although the Bayes optimal classifier is as good as it gets, it still can make mistakes. It is always wrong if a sample does not have the most likely label. We can compute the probability of that happening precisely (which is exactly the error rate): $$\epsilon_{BayesOpt}=1-\mathrm{P}(h_\mathrm{opt}(\mathbf{x})|\mathbf{x}) = 1- \mathrm{P}(y^*|\mathbf{x})$$ Assume for example an email \(\mathbf{x}\) can either be classified as spam \((+1)\) or ham \((-1)\). For the same email \(\mathbf{x}\) the conditional class probabilities are: $$ \mathrm{P}(+1| \mathbf{x})=0.8\\ \mathrm{P}(-1| \mathbf{x})=0.2\\ $$ In this case the Bayes optimal classifier would predict the label \(y^*=+1\) as it is most likely, and its error rate would be \(\epsilon_{BayesOpt}=0.2\).
Why is the Bayes optimal classifier interesting, if it cannot be used in practice? The reason is that it provides a highly informative lower bound of the error rate. With the same feature representation no classifier can obtain a lower error. We will use this fact to analyze the error rate of the \(k\)NN classifier.
While we are on the topic, let us also introduce an upper bound on the error --- i.e. a classifier that we will (hopefully) always beat. That is the constant classifier, which essentially predicts always the same constant independent of any feature vectors. The best constant in classification is the most common label in the training set. Incidentally, that is also what the \(k\)-NN classifier becomes if \(k=n\). In regression settings, or more generally, the best constant is the constant that minimizes the loss on the training set (e.g. for the squared loss it is the average label in the training set, for the absolute loss the median label). The best constant classifier is important for debugging purposes -- you should always be able to show that your classifier performs significantly better on the test set than the best constant.
|

|

|
Good news: As \(n \to\infty\), the \(1\)-NN classifier is only a factor 2 worse than the best possible classifier. Bad news: We are cursed!!In the limit case, the test point and its nearest neighbor are identical. There are exactly two cases when a misclassification can occur: when the test point and its nearest neighbor have different labels. The probability of this happening is the probability of the two red events: \((1\!-\!p(s|\mathbf{x}))p(s|\mathbf{x})+p(s|\mathbf{x})(1\!-\!p(s|\mathbf{x}))=2p(s|\mathbf{x})(1-p(s|\mathbf{x}))\) 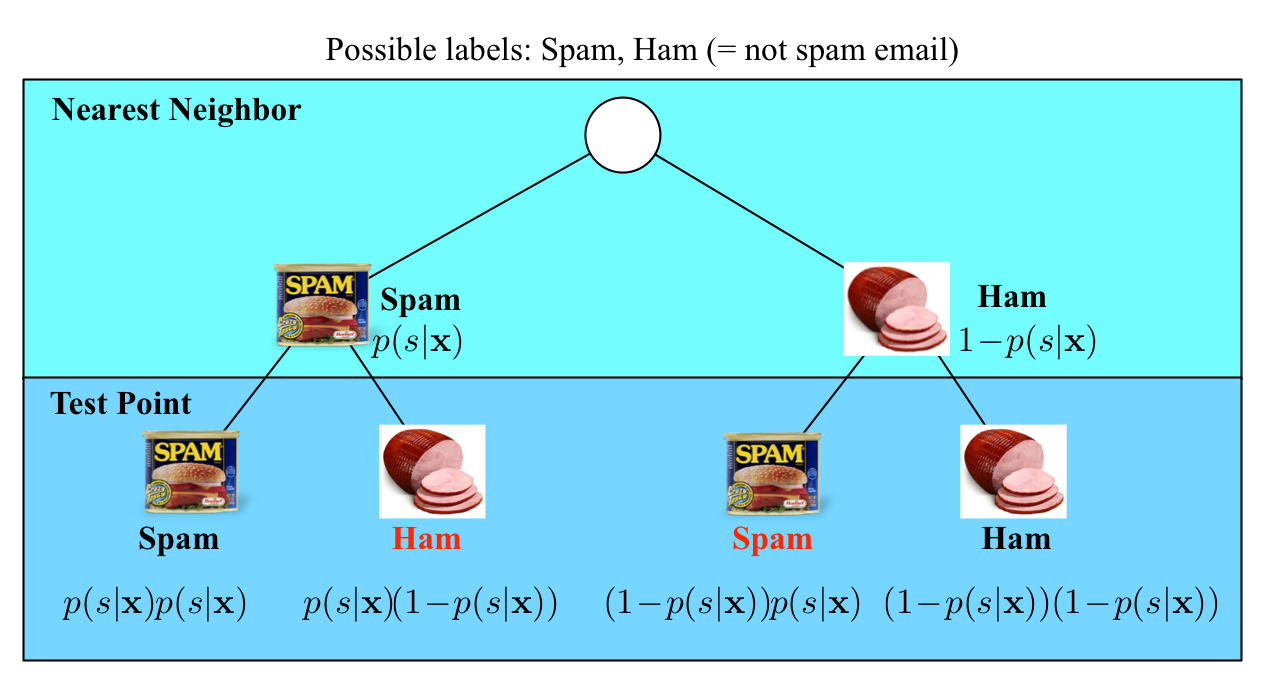
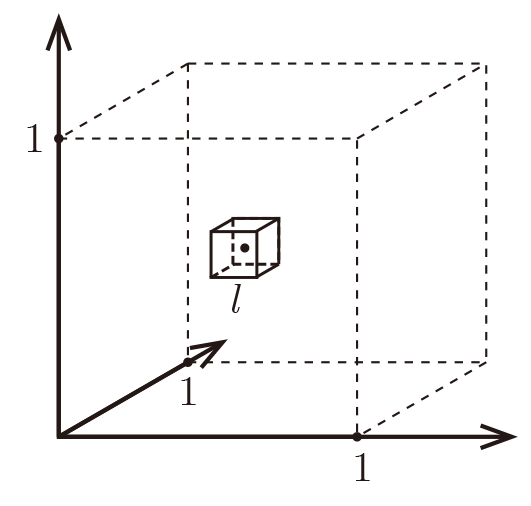
Formally, imagine the unit cube \([0,1]^d\). All training data is sampled uniformly within this cube, i.e. \(\forall i, x_i\in[0,1]^d\), and we are considering the \(k=10\) nearest neighbors of such a test point.
| \(d\) | \(\ell\) | ||
| 2 | 0.1 | ||
| 10 | 0.63 | ||
| 100 | 0.955 | ||
| 1000 | 0.9954 |
So as \(d\gg 0\) almost the entire space is needed to find the \(10\)-NN. This breaks down the \(k\)-NN assumptions, because the \(k\)-NN are not particularly closer (and therefore more similar) than any other data points in the training set. Why would the test point share the label with those \(k\)-nearest neighbors, if they are not actually similar to it?
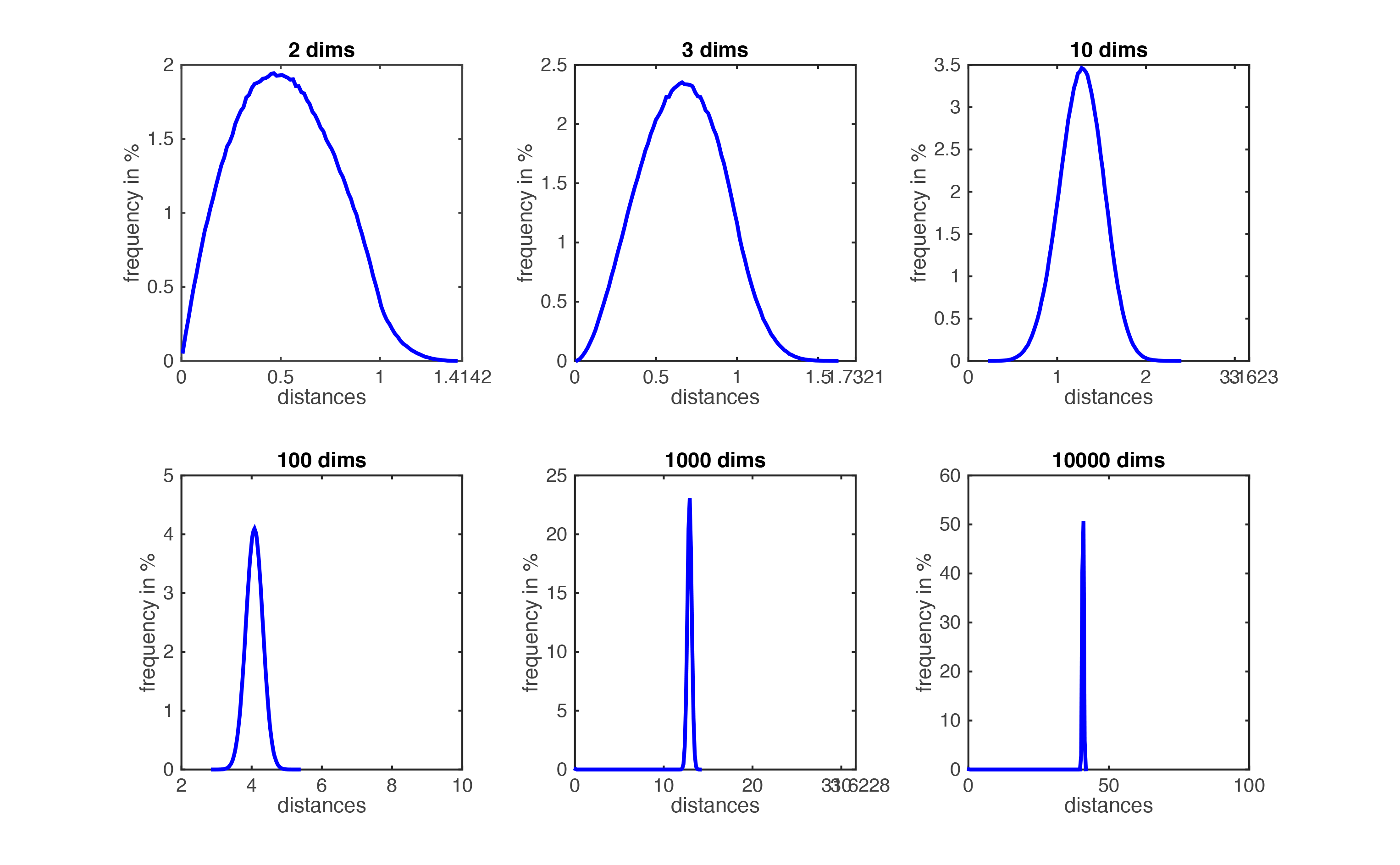
Figure demonstrating ``the curse of dimensionality''. The histogram plots show the distributions of all pairwise distances between randomly distributed points within \(d\)-dimensional unit squares. As the number of dimensions \(d\) grows, all distances concentrate within a very small range.
One might think that one rescue could be to increase the number of training samples, \(n\), until the nearest neighbors are truly close to the test point. How many data points would we need such that \(\ell\) becomes truly small? Fix \(\ell=\frac{1}{10}=0.1\) \(\Rightarrow\) \(n=\frac{k}{\ell^d}=k\cdot 10^d\), which grows exponentially! For \(d>100\) we would need far more data points than there are electrons in the universe...
So the distance between two randomly drawn data points increases drastically with their dimensionality. How about the distance to a hyperplane? Consider the following figure. There are two blue points and a red hyperplane. The left plot shows the scenario in 2d and the right plot in 3d. As long as \(d=2\), the distance between the two points is \(\sqrt{{\Delta x}^2+{\Delta y}^2}\). When a third dimension is added, this extends to \(\sqrt{{\Delta x}^2+{\Delta y}^2+\Delta z^2}\), which must be at least as large (and is probably larger). This confirms again that pairwise distances grow in high dimensions. On the other hand, the distance to the red hyperplane remains unchanged as the third dimension is added. The reason is that the normal of the hyper-plane is orthogonal to the new dimension. This is a crucial observation. In \(d\) dimensions, \(d-1\) dimensions will be orthogonal to the normal of any given hyper-plane. Movement in those dimensions cannot increase or decrease the distance to the hyperplane --- the points just shift around and remain at the same distance. As distances between pairwise points become very large in high dimensional spaces, distances to hyperplanes become comparatively tiny. For machine learning algorithms, this is highly relevant. As we will see later on, many classifiers (e.g. the Perceptron or SVMs) place hyper planes between concentrations of different classes. One consequence of the curse of dimensionality is that most data points tend to be very close to these hyperplanes and it is often possible to perturb input slightly (and often imperceptibly) in order to change a classification outcome. This practice has recently become known as the creation of adversarial samples, whose existents is often falsely attributed to the complexity of neural networks.
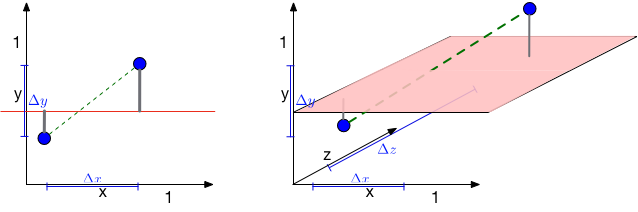
The curse of dimensionality has different effects on distances between two points and distances between points and hyperplanes.
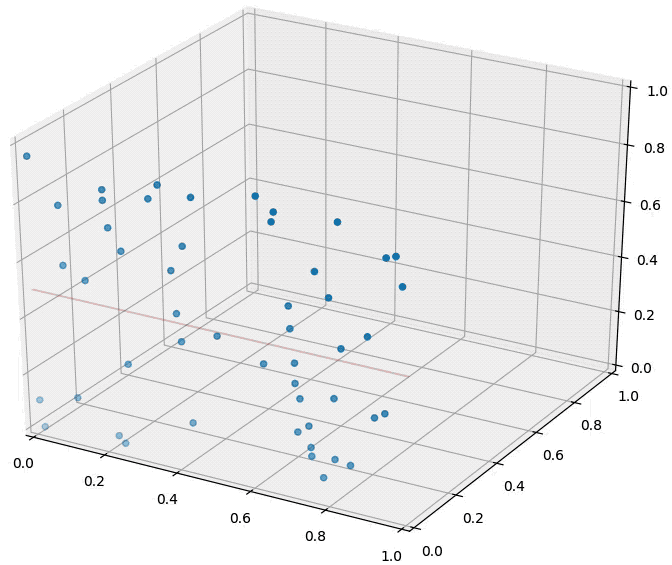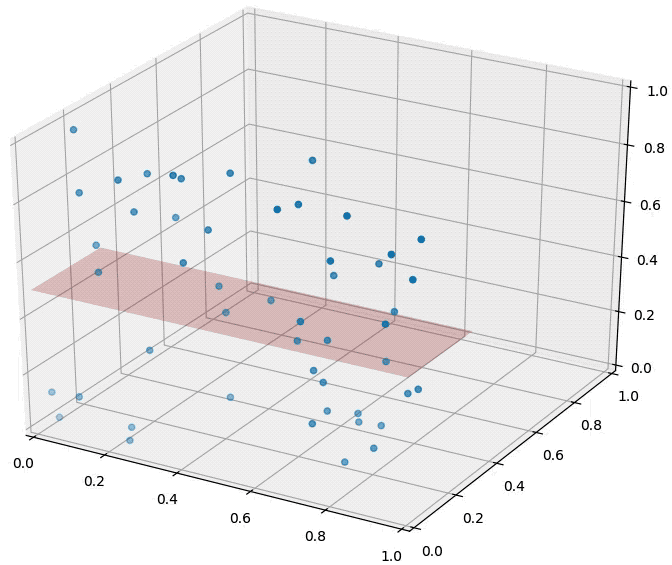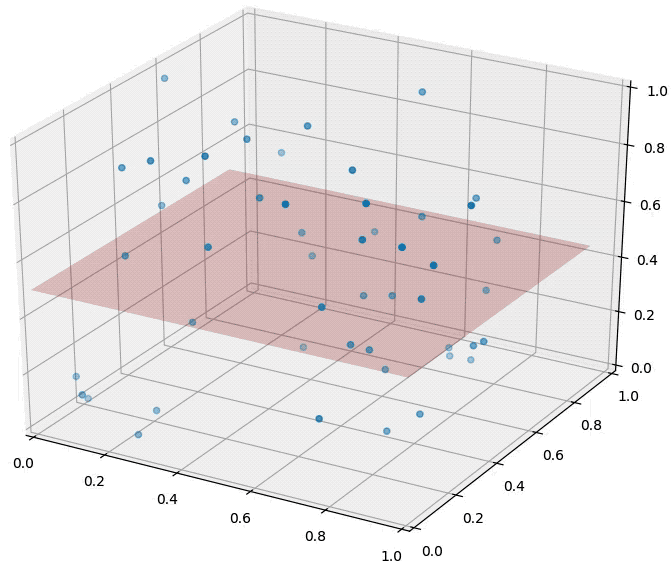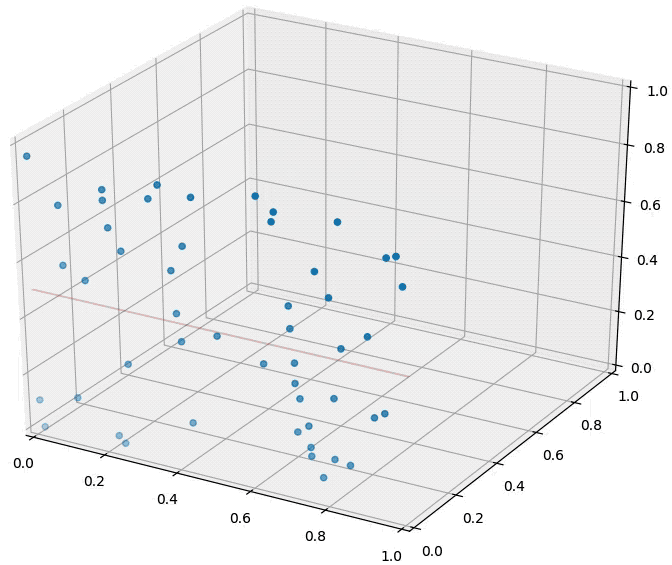
An animation illustrating the effect on randomly sampled data points in 2D, as a 3rd dimension is added (with random coordinates). As the points expand along the 3rd dimension they spread out and their pairwise distances increase. However, their distance to the hyper-plane (z=0.5) remains unchanged --- so in relative terms the distance from the data points to the hyper-plane shrinks compared to their respective nearest neighbors.
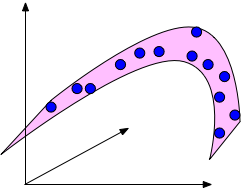
An example of a data set in 3d that is drawn from an underlying 2-dimensional manifold. The blue points are confined to the pink surface area, which is embedded in a 3-dimensional ambient space.