TD-learning, neural
networks, and backgammon
Kimon Tsinteris
David Wilson
1. Introduction
Board games are well suited to demonstrate various approaches of artificial intelligence. They offer challenges of great complexity over a domain that is well defined. Because the rules to games such as checkers, chess, and backgammon lack ambiguity, as does the final outcome, board games provide a good evaluation of the performance of different algorithms and techniques.
This paper
describes a successful approach toward a computer program that plays a good
game of backgammon. Because backgammon incorporates a stochastic process, the
roll of the dice, the game tree space is too large to lend itself to the
traditional method of search. For this reason, past attempts at computer
programs that played backgammon have been largely unsuccessful. A computer program
that succeeded in doing so is a major milestone. The goal of this project was
to recreate this major milestone.
The
approach taken reproduces work done by Gerald Tesauro in 1991. We
re-implemented an early version of his TD-Gammon, a neural network based
program that successfully learns to play backgammon. A framework for the game
of backgammon was written including such things as the board representation,
random dice roll, and valid move generation. A neural network was used and
trained as an evaluation function, with sole output the probability of white
winning. After each roll of the dice, all possible valid moves were calculated
and then subsequent board positions evaluated. As white, the program
consistently chooses the move that maximizes the evaluated output, while as
black, it just chooses the move that minimizes it most.
The truly remarkable aspect of this approach is that the computer program is self-taught. Starting with random initial weights, the neural network is trained through reinforcement learning, in particular using a technique called TD(l). The neural network is trained solely through self-play, which leads it to develop its own positional knowledge concerning the game of backgammon. One of the most exciting repercussions of this, as witnessed by Tesauro and the whole backgammon community, is the creation of a backgammon player free from the biases of existing human knowledge.
2.
Problem Definition and Algorithm
The trained program should act
as both an evaluator and a controller, by utilizing board evaluations to choose
that move that will lead to the best value. It will also, therefore, be
stateless - the network will need as input only a single board description, and
will give the same output for that description regardless of what it has seen
before (excepting differences caused by training of the network.) The neural
network must therefore be embedded within a game-playing framework to achieve
our goal of competent play, because the network by itself cannot choose
moves. We have, then, the
constraints on program design: A neural network evaluation function, embedded
within a framework that ensures correct move choice and provides an interface
from which the network can play against others.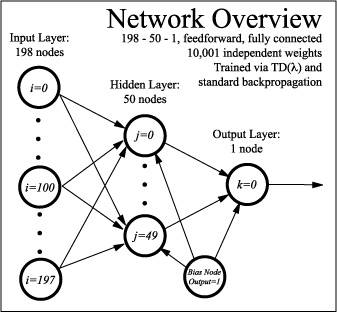
The constraints above lead
naturally into an overall program architecture. A framework is set up that
tracks changes to the board, rolls dice, and ensures the legality of moves. The
framework is also responsible for generating the stream of moves that the
neural network must evaluate. The framework exhibits no intelligence by itself-
it simply finds, and evaluates via the neural network, all legal moves given an
initial board position and roll of the dice.
The neural network, then, is
responsible for the entirety of the intelligent behavior exhibited by the
network. The network consists of a three-layer fully-connected feedforward
network, and maps a board description onto a single output that corresponds,
roughly, to the chance that white will win, given the evaluated board position.
We use a standard sigmoid function at each of the neurons, where a neuron's
output is equal to 1/(1+e-sum), where
sum is the weighted sum of the inputs to that neuron. The sigmoid function
fulfills backpropagation's requirement that the activation function be
continuously differentiable, and at the same time keeps the output within the
0-1 range appropriate for an evaluation intended to describe the white player's
chance of winning.
In designing the inputs to the
network, the decision was made to closely follow Tesauro's original TD-Gammon
program, and have mapped the board position onto an input vector of 198
elements, making no attempt to limit the number of input neurons. There are no
hand-crafted features as part of the inputs; we rely on the network for feature
extraction and use.
A backgammon board consists of
twenty-four board positions, and each of these positions is represented by eight
input neurons. This board representation comprises the first 192 inputs to the
network. For each position, four inputs represent the number of white pieces
and four represent the number of black pieces. This representation is simple --
the first neuron is on if there is one piece on the board at the given
position. The second and first are both on if there are two pieces, and the
first three are on if there are three checkers. The fourth neuron represents
one-half the number of checkers beyond three that are present on the board
position.
The next two inputs represent
the player who is moving; the first is on for a move by white and the second is
on for a move by black. Pieces on the bar are the next two, each input being
one-half the number of checkers on the bar for the corresponding player. Last,
the number of pieces already borne off by each player is represented directly
in the final two inputs. These are the only inputs whose values are ever
expected to exceed unity with any regularity.
These 198 input units are
fully connected to a hidden layer of 50 units, and this hidden layer is in turn
connected to the single output neuron. Each hidden layer neuron, and the output
layer neuron, also have bias inputs whose values are held at unity. The network
configuration can be described in terms of 10001 independent weights governing
the connections between the neurons.
The network was trained using
a fully incremental version of TD-backprogation. Weight changes were calculated
following every move except the first, and the changed weights were used in the
next move's evaluation. The desired output during backpropagation was set to
the evaluation of the neural network at the following move (after the opponent
had made a move, that is.) The procedure at each step was:
Given vector of weights D eligibility trace vector
e(s).
1.) Evaluate board positions using the neural network.
Choose the move with the highest (lowest as black) evaluation. Move.
2.) If this is the end of the game:
Backprop,
with reward of 1 or 0 depending on whether white won or lost.
3.) Else if this was not the first move, then:
a)
Evaluate board.
b)
Calculate error between current evaluation and previous evaluation.
c)
Backprop, using the current evaluation as desired output and the board position
previous to the current move as the input.
End.
Backpropagation procedure:
Given an input vector V and a desired output O.
1) Calculate error E between the network's output on V
and the desired output O.
2) e(s) = (lambda)*e(s) + grad(V)
3) V = V + (alpha)*error(n)*e(s)
where
error(n) is:
For
the weight between hidden node i and the output node, error(i)=E*activation(i)*weight(i)
For
the weigth between input node j and hidden node i, error(j,i)=error(i)*activation(j)*weight(j,i)
The application of temporal
difference learning to game playing has a fairly long history, from Samuel's
checkers player through Tesauro's original TD-Gammon program, providing an
excellent theoretical framework for our work. Though closely following
Tesauro's work to capitalize on this history, our program nonetheless deviates
in certain areas to reduce the complexity (or solve difficulties that arose in
training). The first of these comes form the evaluations created by the
network- while Tesauro expected the network to produce different evaluations
based on which player it was evaluating for, our network always evaluates to
find white's chance of winning- the external framework takes care of using the
highest value for white's move and the lowest for black's. This proved to be
the solution to an initial difficulty that was revealed when the network
quickly saturated to a middle value (approximately 0.5) regardless of the input
board position.
The implementation of the full
eligibility trace algorithm (initial tests used only an approximation) lead to
the first networks that matched the results previous work indicated that the
network should produce. Subjective evidence of learning was apparent as early
as 20,000 games into training, and the network was able to beat the authors
consistently by 90,000 games. Testing against implementations with the
eligibility trace approximation showed the new network winning over 85% of the
games.
3.1 Methodology
The goal of the project was,
of course, the creation of a program that could achieve competency in playing
backgammon. We chose two ways of evaluating our networks performance at this
task: comparison with human expert moves on a set of board positions, and
evidence of learning through testing the network against less-trained versions
of the weight data. As described above, the program went through several
iterations before the current, and relative best, design was found. It is
interesting to note that many of the issues with earlier designs are directly
attributable to faults in the random number generators initially used in
playing the games; that is, networks trained using the standard C library's
rand() function performed noticeably worse than networks trained using a random
number generator with a longer period.
It is likely that a portion of the poor performance of our initial
approximation to TD(l) can be explained by this, though we did not discover the problem
until we had moved to the full implementation of the algorithm and therefore
cannot provide more than circumstantial evidence for this.
Much of the advantage that
self-play offers as a method of training the neural network lies in the fact
that every position will be the result of a backgammon position from an actual
board, rather than being contrived positions that may fail to teach the network
about probabilities or prevent the network from properly generalizing from the
results. Given the average 70-ply in a backgammon game, and the more than
100,000 games played, we find that the network has the advantage of having seen
over 7 million different board positions, something hardly feasible in a
network trained through a crafted set of training data.
3.2
Results
Though we
had originally intended to play the program on FIBS and thus discern its
numerical rating, this turned out to be largely unfeasible given the time
constraints. We had originally planned to act as intermediaries between our
network’s UI and the online opponents. This proved time consuming (e.g.
setting the dice, playing the opponents move, setting the dice, playing back
our networks move), to the point where opponents got bored and walked away from
the game.
We chose 2
different methods to evaluate the performance of our network as a backgammon
player. The first was a round robin tournament between the same network at
various stages in its training. Figure 1 shows that random strategy, reflected
by network trained on only 1 game, is not good for playing backgammon. It
managed to win a single game out of the 1200 games it played against the other
contenders – in fact it is an exceedingly bad strategy. The network after
20,000 games of training did notably better, and a similar improvement can be
seen after it has played 50,000 games against itself. After that, the benefits
of additional training appear to taper off, with the winner of the tournament
being the network after 90,000 games of self-play. We expect that because of
the stochastic nature of the game, and the closeness of the results, a much
longer tournament would be necessary to determine the true winner with much
certainty.

Figure 1
The second method was to compare our fully trained network to current expert opinion on the best opening moves. After 150,000 games of self-play, given the 15 possible opening dice rolls, the network’s move matched expert opinion 8 out of 15 times – more than half the occasions. As can further be seen in Table 1, of the remaining dice rolls, 5 out of 7 times it’s play was a partial match in keeping with the best, and on only 2 occasions was the move different from expert opinion.
3.3
Discussion
The results support our initial hypothesis; that a neural network can be made to excel at backgammon. Even though our implementation provided the network with only a "raw" board encoding as input, and no other relevant information about the game of backgammon, it still managed to do a substantial amount of learning.
|
Dice
Roll |
Best Move
|
Network
Move |
Match |
|
2-1 |
24/23,
13/11 |
24/23,
23/21 |
Partial
|
|
3-1 |
8/5, 6/5 |
8/5, 6/5 |
Yes
|
|
4-1 |
24/23,
13/9 |
24/20,
6/5 |
No |
|
5-1 |
24/23,
13/8 |
24/23,
23/18 |
Partial
|
|
6-1 |
13/7, 8/7 |
13/7, 8/7 |
Yes
|
|
3-2 |
24/21,
13/11 |
24/21,
13/11 |
Yes |
|
4-2 |
8/4, 6/4 |
8/4, 6/4 |
Yes |
|
5-2 |
24/22,
13/8 |
24/22,
13/8 |
Yes |
|
6-2 |
24/18,
13/11 |
24/18,
13/11 |
Yes |
|
4-3 |
24/20,
13/10 |
24/20,
24/21 |
Partial |
|
5-3 |
8/3, 6/3 |
8/3, 6/3 |
Yes |
|
6-3 |
24/18,
13/10 |
24/21,
13/7 |
No |
|
5-4 |
24/20,
13/8 |
24/20,
13/8 |
Yes
|
|
6-4 |
24/18,
13/9 |
24/18,
24/20 |
Partial |
|
6-5 |
24/18,
18/13 |
24/18,
13/8 |
Partial |
Table 1
For the 15 possible opening dice rolls, the moves played by our neural network as compared to the moves considered best by today’s experts [2]. The neural network discovered more than half the best moves, and was completely in error on only 2 occasions.
As can be
seen in Figure 1, the network made significant progress at learning backgammon
through self-play. It started with purely random play and by 20,000 games of
play had already developed strategies such as hitting the opponent, and playing
it safe by covering its pieces. Table 1 shows how with no pre-computed
knowledge, the network by the end of its training, in fact discovered many of
the same opening moves experts deem best. In all aspects, the neural network
displayed phenomenal success at automatic “feature discovery” in
the domain of backgammon.
There are a
number of reasons why computer programs only recently have had success at
playing good backgammon. At each ply, the probabilistic roll of the dice yields
21 different possibilities, each of which on average has 20 possible legal
moves. This makes for a branching factor of ~400. When compared to a branching
factor of 30-40 for chess, backgammon’s high number clearly prohibits
brute search of the game tree. TD-Gammon showed, and this project confirmed,
that relying on a neural network’s sense of positional knowledge does
much better.
Our
implementation uses self-play with reinforcement learning in order to develop
its positional judgment. Instead of being shown a handcrafted set of games, and
imitating expert human opinion, it actually becomes an expert of its own. In
particular by not relying on human interaction for it’s training, it is
freed from some of the existing human biases. In fact, because of more advanced
versions of TD-Gammon, well established opening moves to backgammon have been
re-examined and abandoned. The backgammon community has now accepted TD-Gammon rollout
as the "most reliable method available for analyzing backgammon
plays." [5]
4. Related work
Previous
attempts at writing computer programs that played backgammon had always led to
mediocre backgammon play. In the game of backgammon, there is a branching
factor of several hundred, which makes the brute-force methodology not
feasible. Most commercial programs before 1990 played at a "weak
intermediate level" [5].
Neurogammon
was the first successful attempt to teach a neural network backgammon, and in
fact was TD-Gammon's precursor. By Tesauro, Neurogammon relied on supervised
learning. It was trained through backpropagation on a database of games
recorded by expert backgammon players. Neurogammon managed to achieve a
"strong intermediate level of play" [5]. This approach however is not
infallible. It relies on human knowledge, and sometimes that human knowledge is
flawed. For instance, human game play of backgammon has improved significantly
in the past 20 years.
Tesauro
also released subsequent versions of TD-Gammon that built upon the initial
success. Instead of just using a "raw" board encoding (number of
white and black pieces at each location) as input, a set of handcrafted
features deemed important by experts was also added. This included pre-computed
information such as the probability of being hit, or the strength of a
blockade. The final version of TD-Gammon also included a 2-ply search in making
its move selection. These added features made TD-Gammon the first computer
program to attain strong master level play, equaling the world's best human
players.
5. Further Work
Given further time for
investigations, there are several directions for the program that could prove
worthwhile. Improvements to the backpropagation algorithm hold the most
promise, especially momentum or Q(l), an enhancement of
the temporal difference portion of the algorithm. The most common difficulty we
encountered was found when networks became caught in local minima, and efforts
to overcome this would decrease the number of initial weight configurations
that must be tested to find one that could be called, with any certainty,
near-optimal.
More fundamental changes are
also worth investigating, such as the addition of extra hidden nodes or the use
of crafted features as additional inputs to the network. Preliminary testing
with a larger hidden layer (80 nodes) indicated a very large performance hit,
however, prompting the choice of 50 as the final size for the hidden layer.
However, previous work in this area (especially Tesauro's TD-Gammon) has shown
that raising the network size to 100 or more can have a beneficial impact on
trained performance.
6. Conclusion
Temporal
difference learning yielded surprisingly good results training a neural network
as an evaluation function for the game of backgammon. Furthermore, the use of
self-play for training appears to have in no way hindered the learning process.
Our program clearly shows evidence of feature discovery in the domain of
backgammon, and after sufficient training, plays a good game.
These
findings, mirrored in our results, show that temporal difference learning
applied to neural networks is a viable alternative to traditional search. The
success of TD-Gammon not only reshaped master level play of backgammon, but
also sparked a re-interest in the field. TD(l) is being applied to other board
games such as chess and Othello, with initial findings showing some success.
Though not as dramatic as in backgammon, temporal difference learning appears
to be a good complement to the more traditional search techniques employed by
many today.
7. References
1. Barto, Andrew G and Sutton,
Richard S. Reinforcement Learning: An Introduction. MIT Press, Cambridge, MA, 1998.
2. Damish,
Mar. Backgammon -- Frequently Asked Questions. http://www.cybercom.net/~damish/backgammon/bg-faq.html,
1995.
3. Press, Teukolsky,
Vetterling, and Flannery. Numerical Recipes in C. Cambridge University Press, Cambridge, MA, 1992.
4. Russel, Stuart and Norvig,
Peter. Artficial Intelligence: A Modern Approach. Prentice Hall, Upper Saddle River, NJ. 1995
5. Tesauro,
G (1995). Temporal Difference Learning and TD-Gammon. Communications of the
ACM, 38(3): 58-68.
6. Tesauro, G. (1992).
Practical issues in temporal difference learning. Machine Learning, 8(3-4):257-277
7. Tesauro, G. and Sejnowski,
T. J. (1989). A parallel network that learns to play backgammon. Artificial
Intelligence, 39(3):357-390.