
Music Pictures Talks/Pubs Research Resume Education |

This model is naive and does not give much information about a job, such as priority. Additionally, what if failing to finish a job by its deadline results in catastrophic failure--like nuclear meltdown. One would certainly want to model this in a real-world system. Besides the deadline not providing much information, it is rare that a job will always take a certain amount of time to execute. Typically, there will be a wide range of possible running times for each job, and each running time is associated with a probability that the job will take that much time. The running time, or length, of a job is left to chance. Now, one can see why it may be useful to apply decision theory to short-term scheduling in operating systems. Most of this is very similar to Stochastic Scheduling in systems. The difference is that stochastic schedul- ing typically only defines a probability distribution over running times for a specific job, but does not apply any utility to completing that job at a specific time. By using utilities, we can model all of tra- ditional scheduling, plus add additional power to the model through the use of the utility functions. o Each job has a continuous utility function and a probability distribution that describes the importance and running time of the job. o Maximizes the utility of a real-world system (instead of scheduling by fixed running time or priorities) o Users can have a utility "budget" (such as in a supercomputing system) and assign utility to jobs of their importance over time. o Previous research shows usefulness of utility in database systems [Halpern, Chu, Seshadri, 1999] o Bounded Decision Scheduling (BDS): Is there a schedule such that the total utility is greater than or equal to a bound B? o Optimal Decision Scheduling (ODS): Given a schedule S, is the total utility of S optimal? BDS is NP-Complete. It is reducible to Scheduling with Release Times and Deadlines. ODS is co-NP-Complete. It is reducible to Scheduling with Release Times and Deadlines. In order to efficiently schedule jobs in real systems, we have compiled and tested four heuristics. The test harness takes as input the number of tests to perform, the maximum number of jobs in each test, and the maximum time that a job should take. A random number of jobs of at most the maximum number specified is generated for each test. With equal probability, a job follows either the uniform or normal distribution. Likewise, with equal probability, the utility function associated with each job is either linear, exponential, or hard-deadline. The parameters for each type of utility function are randomly generated. o Probability Distribution x Uniform x Normal o Utility Function x Linear x Exponential x Hard Deadline The second set of graphs only has Linear Utility Functions. One hundred tests were run in all cases. The maximum number of jobs was tested at 50, 100, and 200. The maximum time for each job tested was 10, 50, and 100. In more than 60% of the tests, GERR resulted in the highest overall utility. SEJF, on average, produced the second highest utility, followed by GEBF and lastly FIFO. As the number of jobs increased and the maximum length of the job increased, SEJF was more a more stable algorithm and performed better than GERR. For many small jobs, or few jobs, GERR performed best. The fact that SEJF was more stable and produced better results in the case of many jobs and large running times is surprising since this heuristic does not consider utility when scheduling. This information can be viewed in the graphs published below. 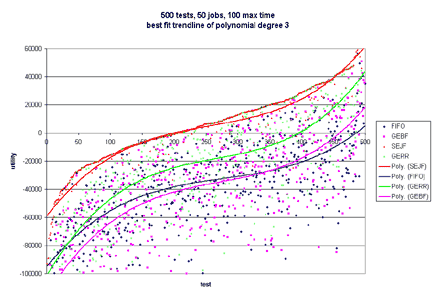 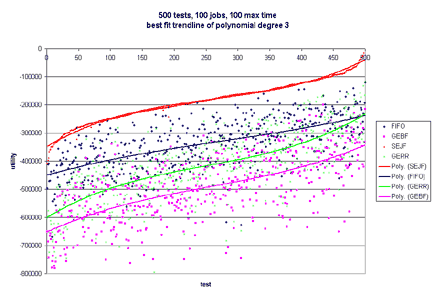 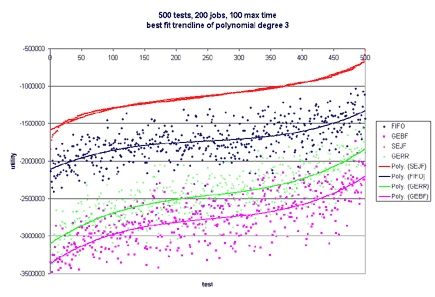 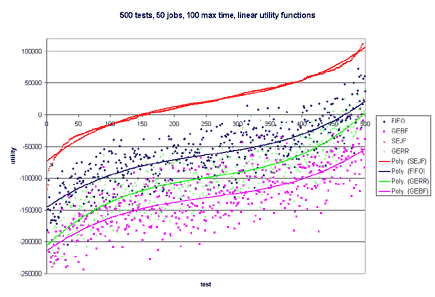 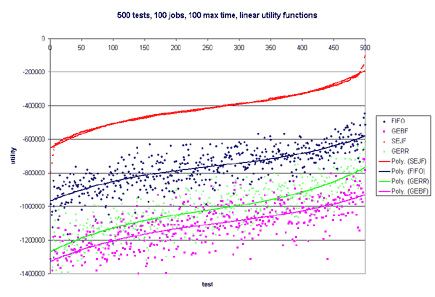 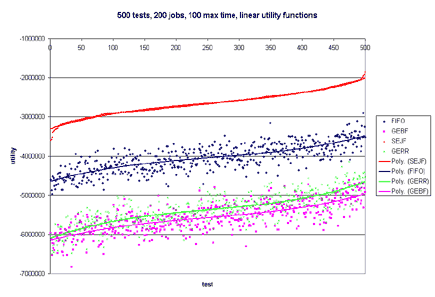 o Why do SEJF and FIFO become much better as the number of jobs increase? o What relationship is there between scheduling and distribution of the jobs (and probability distributions or utility functions)? o Are there other heuristics that perform better that we haven't tested? ... this work is ongoing. |
|
| |