Results
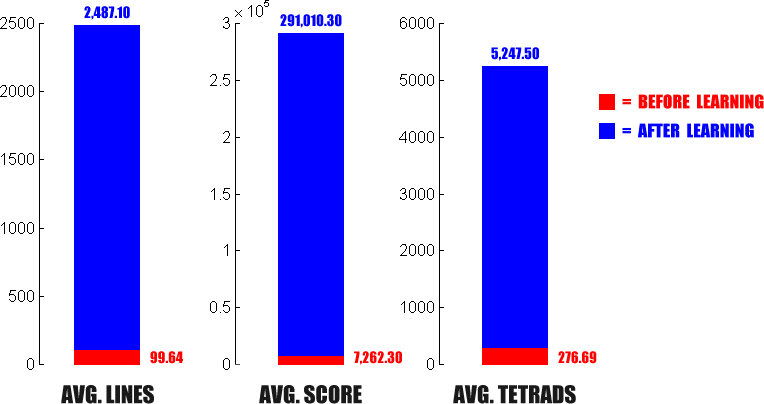
Summary of Results for the Deep Search
If enough iterations are allowed,
Random-Restart Hill-Climbing will eventually find the optimal solution. While I
don’t know if the optimal solution has been found, an extremely good solution
has been found. In total, approximately 50,000 games of Tetris were played by
the learning algorithm. While several of the random initial solutions improved
greatly, none of them came very close to converging to a single maximum. The
initial solution seemed to be a large factor in learning successfully, which
indicates that the shape of the weight-space "surface" is fairly
"bumpy" rather than smoothly curved. The most successful learning
started with the initial state that I selected in the beginning as the setting
I thought would be optimal. However, much improvement was made from the initial
setting.
The path from these weights involved 3 runs – the first one with a step size of
10, 2 passes per run, 100 trials per weight setting, and 0% slack. This
learning process is illustrated in Figure 5. After obtaining the best
performance from this run, I started with the newly "optimal" weights
and executed a run with a step size of 2, 2 passes per run, 100 trials per
weight setting, and 15% slack. This led to a better set of weights. One final
refinement – a run with a step size of 1, 2 passes per run, 100 trials per
weight setting and 0% slack. This lead to the best weight setting I found in
the time permitted. Several other runs from other initial states did come
fairly close to the optimal performance, however.

Figure 5. As the learning algorithm proceeded, the weights
changed from [10 10 10 300 500 10 50 10] to [40 20 10 300 490 70 50 20]. Each
trial consisted of 100 games, so this run consisted of 41 trials in total. The
dashed black line shows the average lines completed per game for each trial.
The vertical red line indicates the best performance, so the weight values that
intersect this line are the best ones. This setting led to the
"optimal" setting obtained after 2 more refined runs (smaller step
size).
When learning, the computer would ignore the
next tetrad (and do a shallow search) in order to save time. The figures listed
below show the difference in performance between the initial setting that I
thought would be optimal and the setting that turned out to be optimal in the
amount of time I had for the learning process. The figures also illustrate that
a small improvement in performance when ignoring the next tetrad can lead to a
huge improvement in performance when playing using the deep search. All games
were played on a 333MHz Pentium II with 96 MB of RAM.
Result Graphs Using the Shallow Search
Result Graphs Using the Deep Search
{kind=link}
{kind=link}
As can be seen from the graphs, the computer
successfully learned to improve its play after playing numerous games and
conducting the local search in the search space of the weights. Although I
haven't been able to locate official high scores for Tetris, I am confident
that no human player has achieved the high score of over 6,000 lines that this
computer player has achieved. At the time the graphs were produced, there was
not much time to play many full games in the optimal setting. Since then, the
computer has scored as high as 6,331 lines and as low as 350 lines. In contrast,
the highest score (in terms of lines) mentioned at www.tetris.com is only 293!
It is possible that a better weight setting exists – a global maximum – that
the local search never found. This can be attributed to time constraints as
well as the enormous size of the 8-dimensional weight space. However, I can
think of one possible improvement that could lead to a better Tetris player.
The weights used are static – they don't change value during the course of the
game. Perhaps the weights should change value based on the current state of the
game board. For instance, some weights could be made a function of the maximum
height of the filled blocks or the total number of filled blocks on the game
board. I experimented with such methods, but they did not improve the
computer's performance, so this type of feature was not implemented..
Future enhancements can also be made to the
search algorithm. For instance, weights could be selected in random order
rather than sequentially. Also, instead of choosing the number of passes
through the weights statically, a feature could be implemented so the algorithm
will continue to pass through the weights until all 8 weights have been
adjusted with no resulting improvement.