The NAS Parallel Benchmarks (version 2.0)[1] consist of five numerical benchmarks written in MPI and are used here to compare MPI over AM and MPI-F in a realistic setting. The running time of each benchmark on 16 thin SP nodes is shown in Table 6.
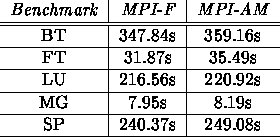
Table 6: Run-times for NAS Class A Benchmarks on 16 Thin SP Nodes
The running times of MPI-AM are close to those achieved by the native MPI-F implementation. The differences shown are due in part to the use of MPICH's generic collective communication routines which are not tuned for the SP. In particular, the all-to-all communication function used by the FT benchmark (MPI_Alltoall) caused unnecessary bottlenecks because all processors try to send to the same processor at the same time, rather than spreading out the communication pattern. Streamlining nonblocking communication routines and implementing collective communication functions directly over AM (rather than using the default MPICH functions built over MPI sends) would improve performance.