Profiling of the basic buffered and rendez-vous protocols uncovered inefficiencies that lead to a number of simple optimizations. The first-fit allocation of receive buffers in the buffered protocol turned out to be a major cost in sending small messages. The optimized implementation uses a binned allocator for small messages (currently 8 1K bins) and reverts to the first-fit algorithm only for ``intermediate'' messages. Using a message for freeing the small buffers was another source of overhead and combining several ``free buffer'' replies into a single message speeds up the execution of the receiver's store handler. These two optimizations, along with some slight code reorganization to cut down on function calls improved the small message latency to within a microsecond of MPI-F.
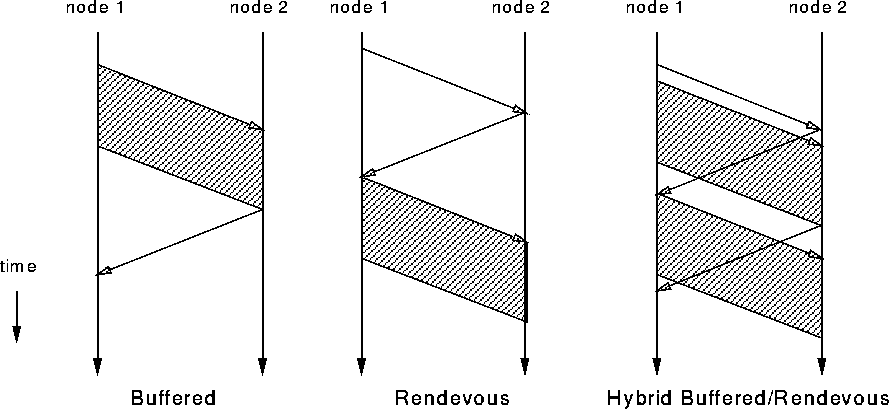
Figure 6: Diagram of Buffered and Rendez-Vous Protocols
Using two distinct strategies for small and large messages means that the implementation has to switch from one to the other at some intermediate message length. This often causes discontinuities in the performance as is the case in MPI-F where the bandwidth achieved using messages of 5 Kbytes is actually lower than with 4 Kbyte messages because of the rendez-vous latency introduced for the larger messages. The optimized MPI-AM augments the rendez-vous protocol by sending out a small prefix (4 Kbytes) of the message into a temporary buffer at the receiver while waiting for the rendez-vous reply. This hybrid buffered/rendez-vous protocol keeps the pipeline full while avoiding excessive buffer space requirements. (If no buffer space can be allocated the hybrid protocol simply reverts to a regular rendez-vous protocol.) By using the hybrid protocol for all messages longer than 8 Kbytes a performance discontinuity is avoided, and the hybrid protocol can reach a higher bandwidth than either the buffered or rendevous protocols could alone (Figure 7).
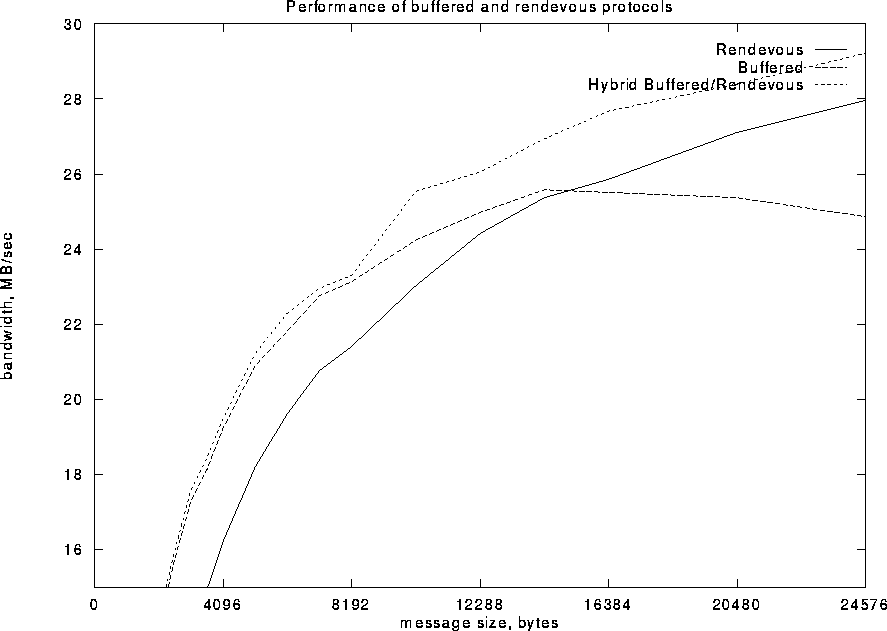
Figure 7: Performance of Buffered and Rendez-Vous Protocols