The major difficulty in layering MPI's basic send (MPI_Send or MPI_Isend) over AM lies in resolving the naming of the receive buffer: am_store requires that the sender specify the address of the receive buffer while message passing in general lets the receiver supply that address. This discrepancy can be resolved either by using a buffered protocol, where the message is stored into some temporary buffer at the receiver and then copied, or by using a rendez-vous protocol, where the receiver sends the receive buffer address to the sender which then stores directly from the send buffer into the receive buffer (Figure 6).
For small messages, the buffered protocol is most appropriate because the extra copy cost is insignificant. Each receiver holds one buffer (currently 16 Kbytes) for every other process in the system. To send a message, the sender allocates space within its buffer at the receiver (this allocation is done entirely at the sender side and involves no communication) and performs an am_store into that buffer. After the receiver has copied the message into the user's receive buffer, it sends a reply to free up the temporary buffer space.
The buffered protocol's requirements are well matched to am_store: the store transfers the data and invokes a handler at the receiving end which can update the MPICH data structures and send a small reply message back using am_reply. If the store handler finds that the receive has been posted it can copy the message and use the reply message to free the buffer space. If a matching receive has not been posted, the message's arrival is simply recorded in an ``unexpected messages'' list and an empty reply is sent back (it is actually used for flow-control by the underlying AM implementation). The buffer space is only freed when a matching receive is eventually posted.
For large messages the copy overhead and the size of the preallocated buffer become prohibitive and a rendez-vous protocol is more efficient. The sender first issues a ``request for address'' message to the receiver. When the application posts a matching receive, a reply containing the receive buffer address is sent back. The sender can then use a store to transfer the message. This protocol may lead to deadlock when using MPI_Send and MPI_Recv because the sender blocks while waiting for the receive buffer address. This is inherent in the message passing primitives and MPI offers nonblocking alternatives (MPI_Isend and MPI_Irecv).
In the implementation of the rendez-vous protocol MPI_Send or MPI_Isend causes a request to be sent to the receiving node. If a matching receive (MPI_Recv or MPI_Irecv) has been posted, the handler replies with the receive buffer address; otherwise the request is placed in the ``unexpected messages'' list and the receive buffer address is sent when the receive is eventually posted (see Figure 5). At the sender side, the handler for the ``receive buffer address'' message is not allowed to do the actual data transfer due to the restrictions placed on handlers by AM. Instead, it places the information in a list, and the store is performed by the blocked MPI_Send or, for nonblocking MPI_Isends by any MPI communication function that explicitly polls the network.
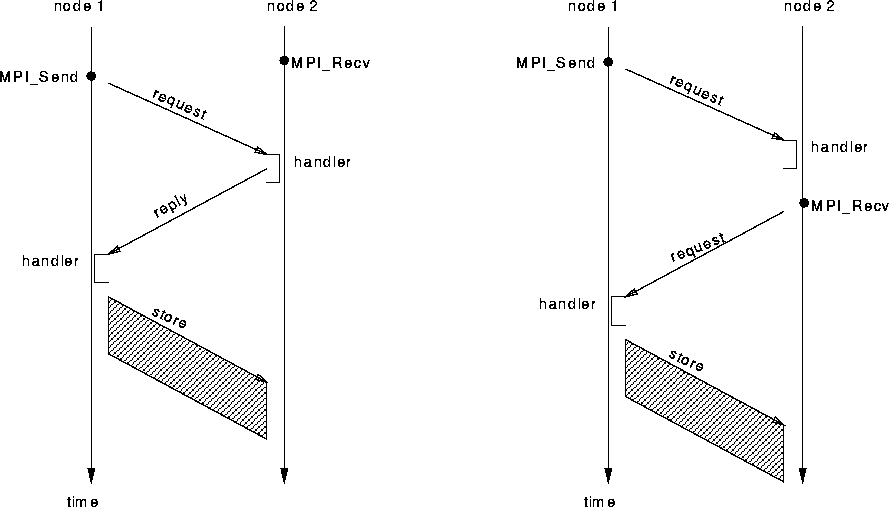
Figure 5: Rendez-vous protocol over AM, when MPI_Recv is posted
before MPI_Send (left) and after MPI_Send (right)
MPI specifies that messages be delivered in order, and the current implementation assumes that messages from one processor to another are delivered in order. Although this is not guaranteed by the Generic Active Messages standard, SP AM does provide ordered delivery. On AM platforms without ordered delivery, a sequence number would have to be added to each store and request message to ensure ordering.
The current MPI-AM uses the polling version of SP AM. To ensure timely dispatch of handlers for incoming messages am_poll is called explicitly in all MPI communication functions which would not otherwise service the network. For applications which have long gaps between calls to MPI functions, a timer may be used to periodically poll for messages, although this has not been tested yet.