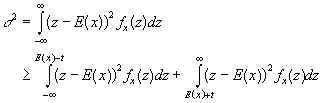- the duration of a CS664 lecture
A random variable is a variable with a range of possible values.
Examples:
- the duration of a CS664 lecture
Random variables (RVs) and be discrete (like x) or continuous (like y). To describe a random variable, you need some notion of the relative likelihood of the different possible values.
A sample assigns a RV one of its possible values, denoted by x=a.
An event is
Examples:
is a sample. It's also an event.
is a sample. It's also an event.
is an event.
A probability measure is a function that defines the probability of all different events.
Example:
The events (x=2) (x=3) (x=4) happen ¼ ½ ¼ of the time. The numbers in the lower row are the probabilities.
More formally, a probability measure is a function P that satisfies the following axioms:
With AB we denote that both events A and B are happening, and with A+B we denote the event A or B is happening. 0 denotes the impossible event, that is, 'AB=0' expresses that the events A and B are mutually exclusive. Condition 2 simply means that one of the events has to occur.
The probability of a sample ( y=a) for a continuous
variable y has the probability P(y=a) = 0, even if the variable takes on this value
quite often and should intuitively have a higher probability than
the assignment of a value that is not even in the range of
possible values.We will see the mathematical reasons for it in
section 2.5.4.
Notice that the statement "a:P(y=a) = 0 is not a contradiction to the second
condition because there are uncountably many events.
A probability distribution Fx(a), also called cumulative density function is a function that associates each value a with the probability of the event (x<=a),
Example:
For a discrete RV x ,
For the above example, the probability distribution looks like
.
A probability density function fy(a) maps each value to the derivative of Fx for that value,
that is, fy(a) = d/da Fy(a).
Basic properties of a probability density function fy are
Now let's try to understand better how probability, distributions and pdf's are related.
There are no probability density functions for discrete variables because their probability distribution functions are also discrete and cannot be derived. The equivalent of a pdf for discrete variables is called probability mass function.
A probability mass function for a discrete RV x is a set of pi's s.t.
for all i: pi >= 0
for all i: pi = P(x=i)
The expectation value m is one of the fundamental quantities which characterize a random variable. The expectation value is also often called mean, average or first moment. It is usually denoted by E(x) or h, but there are also papers in which the notation <x> is used. The expectation value is defined as follows(the definition on the left is for continuous variables y, the one on the right for discrete variables):
.
The expectation for a function g(x) is defined by
.
You can see that the expectation value is just a weighted average of all values, where each possible value is weighted by the probability of its occurence. Another interpretation of the expectation is that if you consider the area below the pdf (the lower envelope of the pdf), the expectation value corresponds to the center of mass for this area.
Notice that the expectation inherits the property of linearity from the integral (or the summation, for that matter), that is
E(x+a*y)= E(x) + a*E(y).
This property allows very often a considerable simplification of the computation of the expectation value. We will see an example of this in section 2.5.7.
The variance of a random variable s2 is another basic property and defined by s2 =E( (x-h)2 ), where h denotes E(x), as mentioned in the last paragraph.
It is also called the second central moment 1.The quantity s is called standard deviation.
Variance and standard deviation measure the spread of a probability density function.
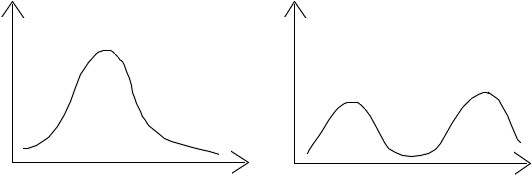
Example:
The pdf on the left has a lower variance and standard deviation than the pdf on the right.
An easy transformation shows that
![]() .
.
This formula is often used in practice to compute the variance.
It is conceivable to use different quantities to measure the center and spread of a pdf. Chebychev's theorem allows us however to make a rigorous argument why expectation and variance are actually a good way to describe probability density functions 2.
Chebychev's inequality
Let x be a RV with expectation m and (finite) variance s2.
Then for all t >= 0,
.
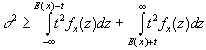 .
.Now consider t = bs. Substitution yields
. Division by s leads to
.
The latter is usually read in the
following way: 'The chance that x differs from m more than b standard deviations
is below ![]() ".
The interesting thing about Chebychev's inequality is that it
holds independently of the actual distribution of x. There exist
stronger theorems for RV's with special distributions.
".
The interesting thing about Chebychev's inequality is that it
holds independently of the actual distribution of x. There exist
stronger theorems for RV's with special distributions.
Conditional probability deals with the probability of events whose likelihood is influenced by the (prior) occurence of other events.
Consider two events A and B. The conditional probability of B given A, written as P(B|A), is defined as
If A has no effect on B then P(B|A)= P(B). Therefore, P(AB)=P(A)*P(B). Events A and B for which this holds are called independent.
Finally, we want to clarify the use of four terms that often occur in the context of non-deterministic computer vision methods.
--------------------------------------
1 Moments are the quantities E(xn) for n= 0,1, ... and central moments are the quantities E((x-h)n) for n= 0,1, ...
2 Note however that mean and variance are not sufficient to specify a pdf uniquely. Moment theory considers the problem of specifying a pdf by its moments.
3Confusingly, in statistics a subset of the population is called a sample, which is different from the use of the term in probability. In probability, a subset of the population would be a set of samples and called an event.