|
[back]
Minimal
Data Set Optimal Classification
James R. Psota, Malik
Magdon-Ismail, Yaser Abu-Mostafa
Abstract.
We are developing classification techniques to detect the nature of
a pump malfunction given pump vibration sensor data. The size of the
data set is very minimal, creating the need for an extremely robust
classifier that incorporates all available information. We investigated
several generalized nearest neighbor and Bayesian classifiers. By incorporating
hints, or information about the problem known independently of the data
set, we show that performance can be significantly improved.
Motivation
and Aims. Honeywell
Corporation approached the Learning Systems Group with a request for
a system that classifies vibration sensor data. They provided us with
information about the pump's prior operation in terms of examples of
frequency responses for numerous faults and fault severities that pump
exhibited. Ultimately, we aim to use our knowledge of the pump's prior
operation to develop classification techniques that can predict the
current mode of the pump in terms of fault and severity of fault. This
system could conceivably forecast severely faulty operation, allowing
necessary repairs and preventing costly malfunctions.
In order
to attain reliable data that describes a pump enduring a fault, the
pump must be forced to exhibit that fault. This turns out to be very
expensive, so we have a very minimal data set. The size of the data
set implies that it contains considerable uncertainty and is therefore
somewhat unreliable. Thus, we must rely on all the information we have
about the problem, including that which is known independently of the
data, to make our classifier as robust as possible.
Research.
We investigated numerous approaches in search of the optimal classifier
for this specific problem specific problem. First we considered the
Nearest Neighbor approach, which classifies based on minimal Euclidean
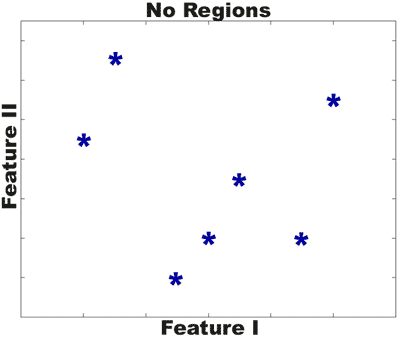
distance. For visualization purposes, we plotted two of the available
twenty-four frequencies and noted the ensuing decision regions (Figure
1). The blue points at the center of each decision region represent
the original data points - the colored, symbolized regions around them
represent classifications that would result if new data arose with those
features. (Of course, this technique is applicable to any number of
dimensions; in our case we used twenty-four dimensions as our input
feature vector was composed of twenty-four components, one for each
frequency.)
 |
 |
Figure
1.
We then
incorporated the Honeywell-provided cost matrix into the nearest neighbor
implementation. It is summarized in the following table, where 0 represents
the normal operation and the pairs (i, k) represent fault i at
severity level k. For example, (2,1) would represent a mildly
severe fault 2. The row represents the actual state while the
column represents the classified state and the entry represents the
cost incurred when the actual state is classified as indicated by the
column. This expert input allows us to nudge the existing decision boundaries
in such a way that, if there is some uncertainty in the measurement,
the cost is minimized.
| |
0 |
(i,1) |
(i,2) |
(i,3) |
(j,1) |
(j,2) |
(j,3) |
| 0 |
0 |
3 |
7 |
9 |
3 |
7 |
9 |
| (i,1) |
3 |
0 |
2 |
4 |
1 |
3 |
5 |
| (i,2) |
3 |
2 |
0 |
2 |
3 |
1 |
3 |
| (i,3) |
7 |
4 |
2 |
0 |
5 |
3 |
1 |
| (j,1) |
3 |
1 |
3 |
5 |
0 |
2 |
4 |
| (j,2) |
3 |
3 |
1 |
3 |
2 |
0 |
2 |
| (j,3) |
7 |
5 |
3 |
1 |
4 |
2 |
0 |
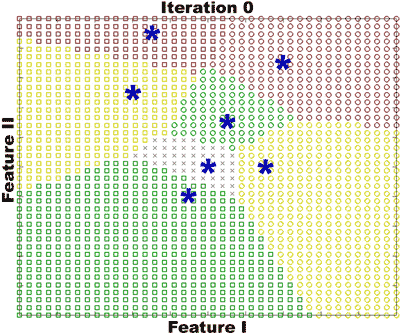
Figure
2 shows that as uncertainty increases, boundaries move by greater amounts
to favor a less consequential decision.
 |
|
Figure
2. Click here or on image for
animated version. Incorporating the cost matrix into nearest neighbor
shows that certain boundaries (normal-medium) vary as uncertainty
increases, whereas others (normal-mild) do not. For the faults
shown, we see that as uncertainty increases this classifier favors a
medium classification over a normal classification.
Although
intuitively reasonable, the nearest neighbor approach isn't optimal
from a probabilistic standpoint because it does not consider variances
and prior probabilities. Thus, we implemented a Bayesian classifier
based on Gaussian class conditional densities. The data provided some
estimates for error bars in those classes where the error bars were
not available. To further incorporate all available data, we implemented
a Bayesian minimal risk classifier to incorporate the cost matrix.
To determine
which components of the data were most relevant to classification, we
performed a principal component analysis. It showed that 90% of the
energy can be summarized in 10 orthogonal directions and 99% can be
summarized in 18 orthogonal directions. These observations will help
in interpreting results.
To make
the data more reliable, we argued that it contains error; we responded
by perturbing each point in such a way that intuitive requirements about
the system's behavior are satisfied (Figure 3). Specifically, these
requirements constitute a monotonicity hint, and it arises from the
following understanding: if the feature vector for the center of a class
moves in a certain direction when the pump progresses from, say, normal
operation to fault F, mild operation, then if the vector
continues to move in the same direction, the pump should eventually
result in fault F, medium operation. Incorporation of
the hint also allows us to estimate values the data set is missing.
For instance, if we do not have data for fault F, severe
operation, but we do have data for fault F, mild and fault
F, medium, we can extrapolate and estimate values for fault
F, severe. We have implemented several working algorithms
for incorporation of the hint. Each algorithm returns the new, monotonic
class centers as well as the price paid for movement.
 |
|
Figure
3. Click here or on image for
animated version. Here we see the "monotonicity algorithm" in action.
Notice that as the points are perturbed, they become more monotonic.
Finally, in iteration 8, we see that the class centers within each fault
are monotonic. The ensuing decision regions are also much more "progressive"
in that a transition from normal to severe is impossible
without first entering through mild and medium severity.
Future
Work. We are awaiting an additional, more-complete data set from
Honeywell; it will enable us to further improve our classifier and test
its performance. Finally, we hope to build a very strong classifier
by first extracting the relevant features using Principal Component
Analysis, making this new data obey monotonicity, and then feeding this
enhanced data to the Bayesian Minimal Risk Classifier. We expect this
combination of methods to give us more reliable results than any solitary
one.
top
|